
Data Crawling with Scrapy
What is Scrapy
Scrapy can be used for 1) extracting the data from websites and 2) saving them in your preferred format. In general, data crawling can be done easily if collecting data is small. However, as your data size gets bigger, number of URLs and that of crawler source codes become complicated to maintain. Scrapy solves the challenges that come from the issue mentioned above.
- modularized with spider, item, pipeline, selector, etc. so that unnecessary reusable programming (called “boilerplate code”) is not required.
- If data size is big, process of data crawling gets slower. To make the process faster, async (asynchronous) operating like Parallel Thread in Python can be used. Scrapy can work asynchronously.
Scrapy Architecture
Fig1 shows the created project directory. I commanded $ scpary startproject companycrawler in the terminal.
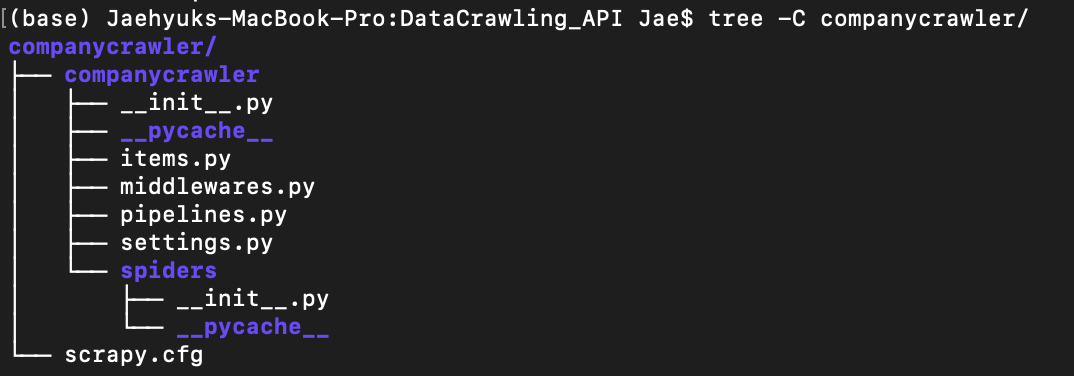
| Fig1. Scrapy Project Directory |
companycrawler/ # project’s Python module, you’ll import your code from here init.py
items.py # project items defined (a class with attributes) to provide functionalities.
middlewares.py # project communicator between the Engine and the Spiders that process spider input (responses) and output (items and request).
pipelines.py # project pipelines that process the extracted items like cleansing, validating, and persistent storing. Think of it as a passage for storing items.
settings.py # project settings file
spiders/ # a directory where you'll later put your spiders of cutomized classes.
__init__.py
...
scrapy.cfg # deploy configuration file
Let me connect the these files and directories to the Scrapy architecture diagram shown below.
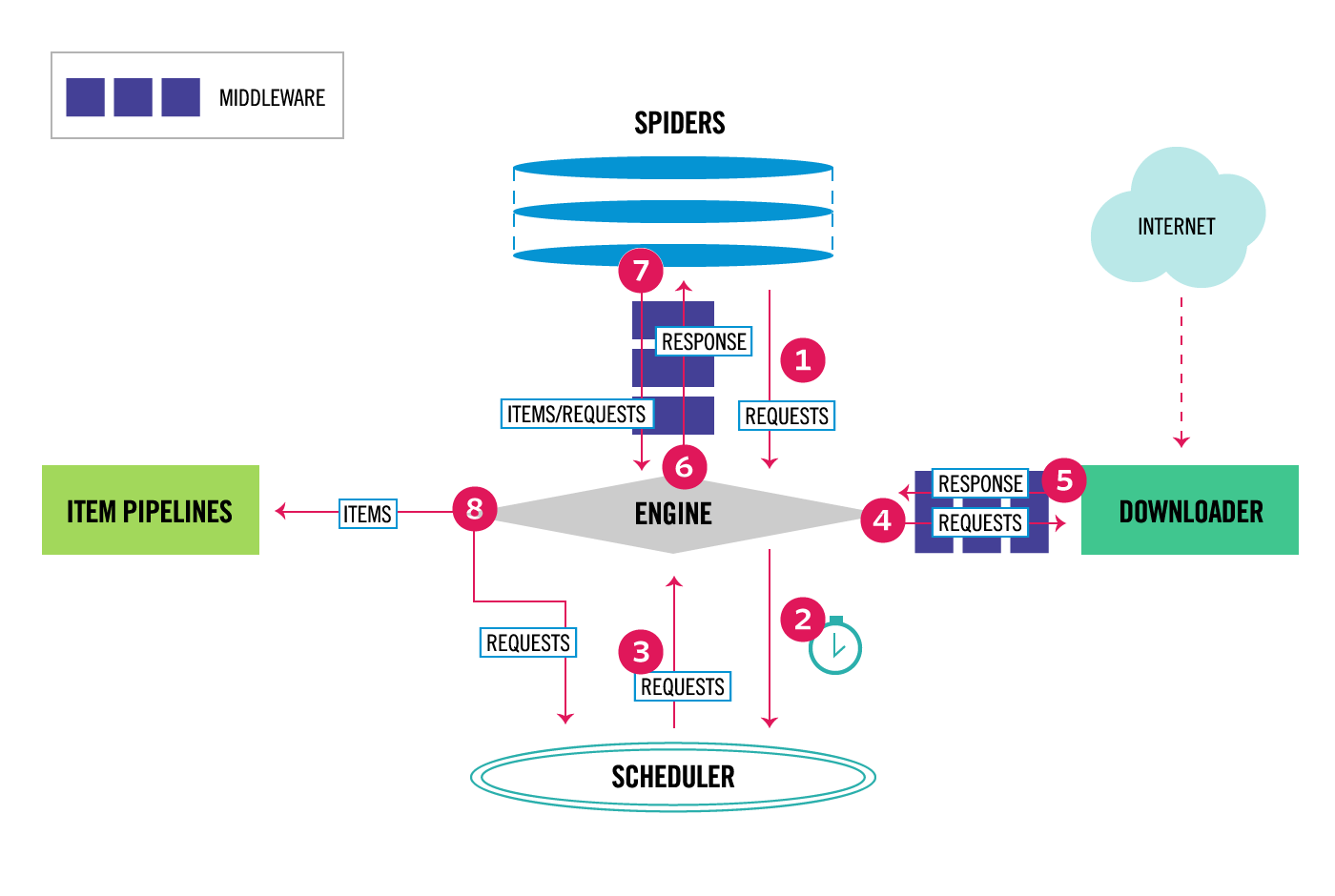
| Fig2. Scrapy Architecture Diagram |
- The Engine gets the initial Requests to crawl from the Spider which is customized classes by users to parse responses and extract items. It can work asynchronously.
- The Engine schedules the Requests in the Scheduler and gets ready for the next Requests from it.
- The Scheduler returns the next Requests to the Engine.
- The Engine sends the Requests to the Downloader through the Downloader Middlewares.
- The Downloader sends the Response, after done with downloading, to the Engine.
- The Engine sends the Response from the Downloader to the Spider for processing.
- The Spider processes the Response and returns scraped items and new Requests to the Engine.
- The Engine sends processed items to the Pipelines and processed Requests to the Scheduler.
These steps can be repeated until there is no more requests from the Scheduler.
Leave a comment