
Data Crawling with Twitter API
Introduction
In the earlier post, I briefly introduced about how API and web work. In this post, let me talk about the practical usage of API: data crawling using Twitter API.
Get Consumer Key (API key) and Access Key (Access token)
If you want access to Twitter’s APIs, you should create a twitter account (if you don’t have one) and apply for a developer account using the new developer portal at developer.twitter.com.
If you want a help for steps in order to prevent to be banned, I recommend this youtube instruction
Then, you should see Apps when you place your cursor on the account (right top corner in the figure shown below).

| Fig1. Twitter Developer Portal|
From your Twitter Apps page, click + create App and you are ready to go.
| Fig2. Twitter Developer Apps Page|
Open Source Libraries
The following libararies are open-source Python libraries for accessing Twitter API. I personally started with tweepy.
- python-twitter by the Python-Twitter Developers
- tweepy by the tweepy Developers
- twitter by the Python Twitter Tools developer team
- TwitterSearch by @ckoepp
- twython by @ryanmcgrath and @mikehelmick
- TwitterAPI by @geduldig
NOTE API and Libraries are different; while API is defined to interact softwares, library is a chunk of running codes for development reusability. So, an API can be embedded in a library.
| Library | API |
|---|---|
| A reusable chunk of codes | interaction between running codes |
| not an API by itself | can be made of several libraries |
Practice
Save Consumer Key and Access Key
The following code is secrete.py file that I separately saved Consumer Key and Access Key.
# API key == consumer_key
consumer_key = "???"
# API secret key == consumer_secrets
consumer_secret = "???"
# Access token == access_key
access_key = "???"
# Access token secret == access_secret
access_secret = "???"
Practice1: World Sentiment Comparison (Superman vs. Batman)
Practice1 is to see how live twitters think about two keywords. The program captures the real-time tweets related to two keywords that you can set up. In this time, let’s compare Superman with Batman.

Importing
First, I imported the necessary libraries and set the credentials (Consumer Key and Access Key).
consumer_key (variable) is set as API key and access_key (variable) is set as Access token.
import tweepy
from textblob import TextBlob
import preprocessor as prep
import statistics
from typing import List
from secrets import consumer_key, consumer_secret, access_key, access_secret
# Authentication:
auth= tweepy.AppAuthHandler(consumer_key, consumer_secret)
api = tweepy.API(auth)
Streaming and Functions Defined: get, clean, classify, and measure.
get_tweets() is to stream the 10 live tweets related to the ‘keyword’ you will set, clean_tweets() is to clean the parsed tweets that contain non-alphabetical characters, get_sentiment() is to measure and return the score of argument ‘tweets’, and generate_average_sentiment_score() is to generate the average scores of two keywords for comparison. The Cursor object helps you to get access to Twitter APIs.
def get_tweets(keyword: str) -> List[str]:
all_tweets=[]
for tweet in tweepy.Cursor(api.search, q=keyword, tweet_mode='extended', lang='en').items(10):
all_tweets.append(tweet.full_text)
return all_tweets
def clean_tweets(all_tweets: List[str]) -> List[str]:
tweets_clean=[]
for tweet in all_tweets:
tweets_clean.append(prep.clean(tweet))
return tweets_clean
def get_sentiment(all_tweets: List[str]) -> List[float]:
sentiment_scores=[]
for tweet in all_tweets:
blob = TextBlob(tweet)
sentiment_scores.append(blob.sentiment.polarity)
return sentiment_scores
def generate_average_sentiment_score(keyword: str) -> int:
tweets = get_tweets(keyword)
tweets_clean = clean_tweets(tweets)
sentiment_scores = get_sentiment(tweets_clean)
average_score = statistics.mean(sentiment_scores)
return average_score
Main
The main started with asking two keywords to check which keyword the live twitters prefer. I inserted ‘superman’ and ‘batman’ to compare.
if __name__ == '__main__':
print('What does the world prefer?')
first_thing = input()
print('...or...')
second_thing = input()
print()
first_score = generate_average_sentiment_score(first_thing)
second_score = generate_average_sentiment_score(second_thing)
if (first_score > second_score):
print(f'the humanity prefers {first_thing} over {second_thing}!')
else:
print(f'the humanity prefers {second_thing} over {first_thing}')
As the result shows, the live twitters, at the moment, prefer batman to superman.
What does the world prefer?
superman
...or...
batman
the humanity prefers batman over superman
Let’s go further how accurately TextBlob classifies positive, negative, and neutral on each text. That is called Sentiment Analysis. using the function ‘get_tweets()’, I saved all the live tweets in variable ‘tweets’.
tweets = get_tweets('superman')
tweets
The following tweets shows the live tweets on the first keyword ‘superman’ at that moment.
['RT @CristianT__T: The Best #superman 🧤🧤 https://t.co/UmXiDDQ4c4',
'@DanSlott WATCHMEN\nPERSEPOLIS\nMAUS\nBATMAN YEAR ONE\nX-MEN GOD LOVES, MAN KILLS\nSECRET WARS\nIDENTITY CRISIS\nBATMAN BLACK MIRROR\nSPIDER-MAN SAGA OF THE ALIEN COSTUME\nALL-STAR SUPERMAN',
'@FeathersandFoes I chose Superman on purpose. His stories are usually uplifting and pretty positive. If you get a chance, the first story arc post Infinite Crisis (one year later) is amazing.',
'@DanSlott Dark Pheonix\nAll Star Superman\nSuperman: Secret Identity\nMister Miracle',
'@cieItae the return of superman',
"RT @Mister_Walsh: Watching Superman: The Movie as I draw today and it's got me itching for a new Supes movies that is full of hope and ligh…",
'RT @DrPopCultureBG: Great Moments in Villainy\n\n#Superman https://t.co/c3kiDO213F',
'@AdamTGorham @Mister_Walsh Frankly it’s the only parts of Snyder’s Superman I like. The flying scene in the arctic with soaring score. \n\nThen the rest happened.',
'Great Moments in Villainy\n\n#Superman https://t.co/c3kiDO213F',
'My superman T-shirt for for me on my birthday by my sweet little strawberry pie cup I love you dear https://t.co/GCrjm5nz69']
Next step was to clean the tweets, using the function ‘clean_tweets()’ and save cleaned tweets in variable ‘tweets_clean’.
tweets_clean=clean_tweets(tweets)
tweets_clean
The following cleaned tweets are shown.
[': The Best',
'WATCHMENPERSEPOLISMAUSBATMAN YEAR ONEX-MEN GOD LOVES, MAN KILLSSECRET WARSIDENTITY CRISISBATMAN BLACK MIRRORSPIDER-MAN SAGA OF THE ALIEN COSTUMEALL-STAR SUPERMAN',
'I chose Superman on purpose. His stories are usually uplifting and pretty positive. If you get a chance, the first story arc post Infinite Crisis (one year later) is amazing.',
'Dark PheonixAll Star SupermanSuperman: Secret IdentityMister Miracle',
'the return of superman',
": Watching Superman: The Movie as I draw today and it's got me itching for a new Supes movies that is full of hope and ligh",
': Great Moments in Villainy',
'Frankly its the only parts of Snyders Superman I like. The flying scene in the arctic with soaring score. Then the rest happened.',
'Great Moments in Villainy',
'My superman T-shirt for for me on my birthday by my sweet little strawberry pie cup I love you dear']
Can you see the 9th tweet ‘Great Moments in Villainy’? What do you think of its classification, positive or negative? Let’s check how the function get_sentiment() classifies it.
sentiment_scores = get_sentiment(tweets_clean)
sentiment_scores
[1.0,
-0.20833333333333331,
0.17954545454545456,
-0.275,
0.0,
0.24318181818181817,
0.8,
0.0,
0.8,
0.22083333333333333]
The score goes from -1 (negative) to 1 (positive). That tells how each tweeter feel on the keyword ‘superman’. The 9th tweet ‘Great Moments in Villainy’ was scored 0.8, which means that the tweeter felt extremely positive on ‘superman’ at that time. However, (s)he actually talks about ‘villainy’, not ‘superman’. Now, we know that it is misclassified. Practice2 will show performance of sentiment analysis between TextBlob and NLTK Vader. I chose these two packages because they are fast and accurate enough for a tremendous amount of text data. If you interested in more details on performance comparison over Vader, IBM Watson, or TextBlob, check here.
If you want to see the code, check here
Practice2: Twitter Streaming and Visualizing (Trump)
Practice2 is to see how live twitters think about the keyword and we will compare performance of NLTK Vader and TextBlob. The program captures the real-time tweets related to the keyword that you can set up. In this time, let’s check how people think of President Trump (i.e. keyword=’Trump’).

Importing
Similar to Practice1, I imported the necessary libraries and set the credentials (Consumer Key and Access Key).
import csv
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns; sns.set(style='whitegrid')
import re
import json
import time
import warnings
from wordcloud import WordCloud, STOPWORDS
## NLP operation on text
import nltk
nltk.download('vader_lexicon')
from nltk.sentiment.vader import SentimentIntensityAnalyzer
# To consume Twitter's API
import tweepy
from tweepy import Stream
from tweepy import StreamListener
from secrets import consumer_key, consumer_secret, access_key, access_secret
# To identify the sentiment of text
from textblob import TextBlob
from textblob.sentiments import NaiveBayesAnalyzer
# ignoring all the warnings
warnings.filterwarnings("ignore",category=DeprecationWarning)
%matplotlib inline
I entered the keyword ‘trump’ to see what emotional tweets about President Trump the live twitters have.
print('Which keyword you want to check on real-time twitter?')
KEYWORDS = input()
Which keyword you want to check on real-time twitter?
Trump
Then, I defined the filename in the constant ‘OUTPUT_NAME’ added to ‘.csv’ to output a csv file. Since streaming goes forever unless you don’t command when to stop, a limit of 10 (value of the constant ‘THRESHOLD’ can be flexible depending on user).
# rename the output file.
OUTPUT_NAME=re.sub("AND | OR", "_", KEYWORDS.replace('"',"")).replace(' ', "")
OUTPUT_FILE = OUTPUT_NAME+".csv"
# number of tweets to capture.
THRESHOLD = 10
Streaming and Saving Live Streaming Data
Now, the class MyStreamListener() was built to the tweet listener class. I customized the class to make it enable to inherit from the tweepy.StreamListener, count number of tweets it is currently storing to limit, and store it in a JSON format.
Whenever 10 tweets are saved, it prints to show it is working.
class MyStreamListener(tweepy.StreamListener):
def __init__(self, api=None):
super(MyStreamListener, self).__init__()
self.num_tweets = 0
self.file = open(OUTPUT_FILE, 'w')
def on_status(self, status):
tweet = status._json
self.file.write(json.dumps(tweet)+'\n')
self.num_tweets += 1
# Stops streaming when it reaches the limit
if self.num_tweets <= THRESHOLD:
if self.num_tweets %10 ==0:
print(f'Numbers of tweets caught so far: {self.num_tweets}')
return True
else:
return False
self.file.close()
def on_error(self, status):
print("Error detected")
The live tweets streaming was started after permission of accessing Twitter APIs by using Consumer and Access keys that authenticate the user. To grab the only tweets related to the keywords ‘trump’, filter() was set for the keyword ‘trump’ tracker and language (‘en’).
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_key, access_secret)
api = tweepy.API(auth, wait_on_rate_limit=True,
wait_on_rate_limit_notify=True)
tweets_listener = MyStreamListener()
stream = tweepy.Stream(api.auth, tweets_listener)
stream.filter(track=[KEYWORDS], languages=["en"])
Loading and Cleaning the Data
The following code snippet is for loading the Twitter live data that saved in a JSON format.
# Initialize empty list to store tweets
tweets_data = []
# Open connection to file
with open(OUTPUT_FILE, "r") as tweets_file:
# Read in tweets and store in list
for line in tweets_file:
tweet = json.loads(line)
tweets_data.append(tweet)
The id_extractor() is defined to extract the live user names who tweeted about the keyword ‘trump’ so that if you are interested in who wrote the tweet texts, you can search.
def id_extractor(data: list):
name_list = []
for i in range (len(data)):
name_list.append(data[i]['user']['screen_name'])
return pd.DataFrame(name_list)
user_names = id_extractor(tweets_data)
user_names
| 0 | |
|---|---|
| 0 | DrRickF |
| 1 | PauliePops1 |
| 2 | TheRealAZJhawks |
| 3 | PainterMom101 |
| 4 | YouEndorse |
| 5 | ICBubbleGum |
| 6 | tahitianspecial |
| 7 | CrystalScurr |
| 8 | Qnited_We_Stand |
| 9 | SassyP100 |
| 10 | CynthiaMsnene |
The clean_tweet() is defined to clean a tweet text by removing special characters so that NLP packages like TextBlob or NLTK Vader can read it corrextly.
def clean_tweet(tweet):
'''
To clean tweet text by removing special characters
'''
cleaned_tweet = ' '.join(re.sub("(@[A-Za-z0-9]+) | ([^0-9A-Za-z \t]) | (\w+:\/\/\S+)",
" ", tweet).split())
return cleaned_tweet
The full_text_extractor() is defined to extract a full tweet text. Remember the saved file is in a JSON format; mixture of list and dictionary. I grabbed created date (created_at), language (lang), tweet text (text), and user’s name (user_name). If contents of a tweet text is longer, such tweet texts are cut off. Thus, the full_text_extractor() can snatch them for you.
def full_text_extractor(data: list):
'''
To extract full text from each user.
'''
full_text_list = []
for i in range (len(data)):
# if there is 'extended_tweet', clean the full_text and append it to the full_text_list.
if tweets_data[i].__contains__('extended_tweet'):
full_text_list.append(clean_tweet(tweets_data[i]['extended_tweet']['full_text']))
# if there is 'retweeted_status' and extended_tweet in it, clean the full_text and
# append it to the full_text_list. Otherwise, clean and append the text.
elif tweets_data[i].__contains__('retweeted_status'):
if tweets_data[i]['retweeted_status'].__contains__('extended_tweet'):
full_text_list.append(clean_tweet(clean_tweet(tweets_data[i]['retweeted_status']['extended_tweet']['full_text'])))
else:
full_text_list.append(clean_tweet(clean_tweet(tweets_data[i]['text'])))
else:
full_text_list.append(clean_tweet(tweets_data[i]['text']))
return pd.DataFrame(full_text_list)
The following shows the full texts of the ‘trump’ that the full_text_extractor() snatched.
# To check what the full_texts is.
full_texts=full_text_extractor(tweets_data)
print(full_texts)
0
0 Speaking of yard signs- i’ve been seeing Trump...
1 RT @catturd2: President Trump owned the Democr...
2 Every single eligible American should have the...
3 From a friend: An anguished question from a Tr...
4 RT @TheOnion: Trump Slaughters Dozens Of Ameri...
5 RT @TweetSusieTweet: Trump on Mount Rushmore. ...
6 Trump is about to cut out the middlemen in pha...
7 No matter what YES
8 RT @RealBrysonGray: Keep sharing this to make ...
9 RT @RyanAFournier: Trump: Authorizes $430 mill...
10 RT @thekjohnston: This is why trump built appr...
From the selective columns of created date (created_at), language (lang), tweet text (text), and user’s name (user_name), I replaced the cut-off tweet texts with the full texts and inserted user_name column and its corresponding values. The df.text[5] shows its full text.
df = pd.DataFrame(tweets_data, columns=['created_at','lang', 'text'])
# store user names
df['user_name']=user_names
# replace texts with full texts if there is any
df['text']=full_texts
# convert to datetime
df['created_at'] = pd.to_datetime(df.created_at)
df.text[5]
'RT @TweetSusieTweet: Trump on Mount Rushmore. Cheers from Australia! Credit: @moir_alan'
print(len(df))
df.head(3)
11
<div>
<style scoped>
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>created_at</th>
<th>lang</th>
<th>text</th>
<th>user_name</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>2020-08-10 06:57:25+00:00</td>
<td>en</td>
<td>Speaking of yard signs- i’ve been seeing Trump...</td>
<td>DrRickF</td>
</tr>
<tr>
<th>1</th>
<td>2020-08-10 06:57:25+00:00</td>
<td>en</td>
<td>RT @catturd2: President Trump owned the Democr...</td>
<td>PauliePops1</td>
</tr>
<tr>
<th>2</th>
<td>2020-08-10 06:57:25+00:00</td>
<td>en</td>
<td>Every single eligible American should have the...</td>
<td>TheRealAZJhawks</td>
</tr>
</tbody>
</table>
</div>
The textblob_analyzer() is defined to classify a tweet into three categories of emotions: positive, negative, or neutral to identify the tweeters’ sentiments toward the keyword ‘trump’.
def textblob_analyzer(tweet):
'''
To classify sentiment positive, negative, or neutral
'''
# create TextBlob object of passed tweet text
analysis = TextBlob(tweet)
# set sentiment
if analysis.sentiment.polarity > 0:
return 'positive'
elif analysis.sentiment.polarity < 0:
return 'negative'
elif analysis.sentiment.polarity == 0:
return 'neutral'
Similarly, the vader_analyzer() is defined to compare its performance with TextBlob. The neutrality condition is if score is between -0.05 and 0.05 (i.e. \(-0.5 \leq \text{score} \leq 0.5\)).
sid = SentimentIntensityAnalyzer()
def get_vader_score(tweet):
# Polarity score returns dictionary
score = sid.polarity_scores(tweet)
return score
def vader_analyzer(tweet):
'''
To classify sentiment positive, negative, or neutral
'''
# create TextBlob object of passed tweet text
score = get_vader_score(tweet)['compound']
# set sentiment
if score >= 0.05:
return 'positive'
elif score <= -0.05:
return 'negative'
else:
return 'neutral'
Both functions are applied to the ‘text’ column in the dataframe ‘df’ and results were added to new columns ‘TextBlob’ and ‘Vader’.
# See how the df looks.
df['TextBlob']=df['text'].apply(lambda tweet: textblob_analyzer(tweet))
df['Vader']=df['text'].apply(lambda tweet: vader_analyzer(tweet))
df
| created_at | lang | text | user_name | TextBlob | Vader | |
|---|---|---|---|---|---|---|
| 0 | 2020-08-10 06:57:25+00:00 | en | Speaking of yard signs- i’ve been seeing Trump... | DrRickF | positive | positive |
| 1 | 2020-08-10 06:57:25+00:00 | en | RT @catturd2: President Trump owned the Democr... | PauliePops1 | positive | negative |
| 2 | 2020-08-10 06:57:25+00:00 | en | Every single eligible American should have the... | TheRealAZJhawks | positive | positive |
| 3 | 2020-08-10 06:57:25+00:00 | en | From a friend: An anguished question from a Tr... | PainterMom101 | negative | positive |
| 4 | 2020-08-10 06:57:25+00:00 | en | RT @TheOnion: Trump Slaughters Dozens Of Ameri... | YouEndorse | neutral | positive |
| 5 | 2020-08-10 06:57:25+00:00 | en | RT @TweetSusieTweet: Trump on Mount Rushmore. ... | ICBubbleGum | neutral | positive |
| 6 | 2020-08-10 06:57:25+00:00 | en | Trump is about to cut out the middlemen in pha... | tahitianspecial | positive | negative |
| 7 | 2020-08-10 06:57:25+00:00 | en | No matter what YES | CrystalScurr | neutral | positive |
| 8 | 2020-08-10 06:57:25+00:00 | en | RT @RealBrysonGray: Keep sharing this to make ... | Qnited_We_Stand | negative | positive |
| 9 | 2020-08-10 06:57:25+00:00 | en | RT @RyanAFournier: Trump: Authorizes $430 mill... | SassyP100 | negative | negative |
| 10 | 2020-08-10 06:57:25+00:00 | en | RT @thekjohnston: This is why trump built appr... | CynthiaMsnene | neutral | neutral |
The following code snippet is to grab the classified values. Those if conditions are in the case that a value for any of group can be zero.
# Two analysis
textBlob_results=df.TextBlob.value_counts().sort_index(ascending=False)
if Cond_TextBlob:
textBlob_results['positive']=(df['TextBlob']=='positive').values.sum()
textBlob_results['neutral']=(df['TextBlob']=='neutral').values.sum()
textBlob_results['negative']=(df['TextBlob']=='negative').values.sum()
Vader_results=df.Vader.value_counts().sort_index(ascending=False)
Cond_Vader= (Vader_results.positive == 0) or (Vader_results.neutral == 0) or (Vader_results.negative == 0)
if Cond_Vader:
Vader_results['positive']=(df['Vader']=='positive').values.sum()
Vader_results['neutral']=(df['Vader']=='neutral').values.sum()
Vader_results['negative']=(df['Vader']=='negative').values.sum()
Here, you can see the values for each group.
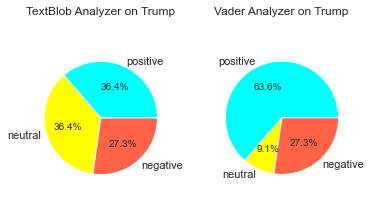
textBlob_results
positive 4
neutral 4
negative 3
Name: TextBlob, dtype: int64 ```python Vader_results ```
positive 7
neutral 1
negative 3
Name: Vader, dtype: int64
Pie plot is used to compare the performance of both TextBlob and Vader.
#plot Pie plot.
if len(df) != 0:
fig, ax = plt.subplots(1,2)
label_list=['positive','neutral','negative']
colors_emotion = ['cyan','yellow','tomato']
explodes_emotion = [0,0,0]
#axis 1 for TextBlob analyzer
ax[0].pie(list(textBlob_results),labels=label_list,colors=colors_emotion,explode=explodes_emotion,
autopct='%1.1f%%', shadow=False)
ax[0].set_title(f'TextBlob Analyzer on {KEYWORDS}')
ax[0].axis('equal')
#axis 2 for Vader analyzer
ax[1].pie(list(Vader_results),labels=label_list,colors=colors_emotion,explode=explodes_emotion,
autopct='%1.1f%%', shadow=False)
ax[1].set_title(f'Vader Analyzer on {KEYWORDS}')
ax[1].axis('equal')
fig.tight_layout(pad=4.0)
plt.show()
| Fig3. Comparison between TextBlob and Vader|
Let’s group the data into three, based on Vader, and check some samples if they are reasonably classified.
# Group the people who have the similar opinions on
# keyword.
pos_group=df[df['Vader']=='positive']
neg_group=df[df['Vader']=='negative']
neut_group=df[df['Vader']=='neutral']
pos_group
| created_at | lang | text | user_name | TextBlob | Vader | |
|---|---|---|---|---|---|---|
| 0 | 2020-08-10 06:57:25+00:00 | en | Speaking of yard signs- i’ve been seeing Trump... | DrRickF | positive | positive |
| 2 | 2020-08-10 06:57:25+00:00 | en | Every single eligible American should have the... | TheRealAZJhawks | positive | positive |
| 3 | 2020-08-10 06:57:25+00:00 | en | From a friend: An anguished question from a Tr... | PainterMom101 | negative | positive |
| 4 | 2020-08-10 06:57:25+00:00 | en | RT @TheOnion: Trump Slaughters Dozens Of Ameri... | YouEndorse | neutral | positive |
| 5 | 2020-08-10 06:57:25+00:00 | en | RT @TweetSusieTweet: Trump on Mount Rushmore. ... | ICBubbleGum | neutral | positive |
| 7 | 2020-08-10 06:57:25+00:00 | en | No matter what YES | CrystalScurr | neutral | positive |
| 8 | 2020-08-10 06:57:25+00:00 | en | RT @RealBrysonGray: Keep sharing this to make ... | Qnited_We_Stand | negative | positive |
Check a tweet text sample in the positive group, which seems more like neutral rather than positive.
# Check a text in the positive group
pos_group.text[2]
"Every single eligible American should have the opportunity to vote-by-mail this November. If it's good enough for Donald Trump then it's good enough for you and me."
I measured scores and process time, using the functions shown below.
Vstart = time.time()
print(f'Vader: {get_vader_score(pos_group.text[2])}')
Vend = time.time()
print('vs')
Tstart = time.time()
print(f'TextBlob: {TextBlob(pos_group.text[2]).sentiment}')
Tend = time.time()
print('vs')
Nstart = time.time()
print(f'TextBlob w/ NB: {TextBlob(pos_group.text[2], analyzer=NaiveBayesAnalyzer()).sentiment}')
Nend = time.time()
Vader: {'neg': 0.0, 'neu': 0.736, 'pos': 0.264, 'compound': 0.8225}
vs
TextBlob: Sentiment(polarity=0.22142857142857142, subjectivity=0.40238095238095245)
vs
TextBlob w/ NB: Sentiment(classification='pos', p_pos=0.7772960377509671, p_neg=0.22270396224903263)
print(f'Vader: {Vend-Vstart} s, TextBlob: {Tend-Tstart} s, TextBlob: {Nend-Nstart} s')
Vader: 0.0016090869903564453 s, TextBlob: 0.0011258125305175781 s, TextBlob: 4.698314905166626 s
The tweet text sample is classified positive for all the cases, but scores are different. If neutrality condition is differently set up, Vader can be better. Moreover, despite the duration TextBlob without NB is the fastest, Vader is useful for the sentiment analysis tasks like movie reviews or book reviews.
neg_group.text
| created_at | lang | text | user_name | TextBlob | Vader | |
|---|---|---|---|---|---|---|
| 1 | 2020-08-10 06:57:25+00:00 | en | RT @catturd2: President Trump owned the Democr... | PauliePops1 | positive | negative |
| 6 | 2020-08-10 06:57:25+00:00 | en | Trump is about to cut out the middlemen in pha... | tahitianspecial | positive | negative |
| 9 | 2020-08-10 06:57:25+00:00 | en | RT @RyanAFournier: Trump: Authorizes $430 mill... | SassyP100 | negative | negative |
The tweet text samples from the negative group. The text can be neutral or negative. Vader seems better for analysis.
words=neg_group.text[6]
words
'Trump is about to cut out the middlemen in pharmaceutical markets. This is huge Right after announcing that, he says “So I have a lot of enemies out there, this may be the last time you see me for awhile.” Is he saying big pharma is plotting to kill him?'
Let’s look at what the user of this guys who wrote above think, using the wordcloud.
stopwords = set(STOPWORDS) # pre-defined words to ignore
# adding extra words to ignore:
# many tweets contain RT in the text, and we know the tweets are about Donald Trump
stopwords.update([KEYWORDS])
wordcloud = (WordCloud(background_color="white", # easier to read
max_words=50, # let's no polute it too much
stopwords=stopwords) # define words to ignore
.generate(words)) # generate the wordcloud with text
plt.figure(figsize=(15,10)) # make the plot bigger
# Show the plot (interpolation='bilinear' makes it better looking)
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
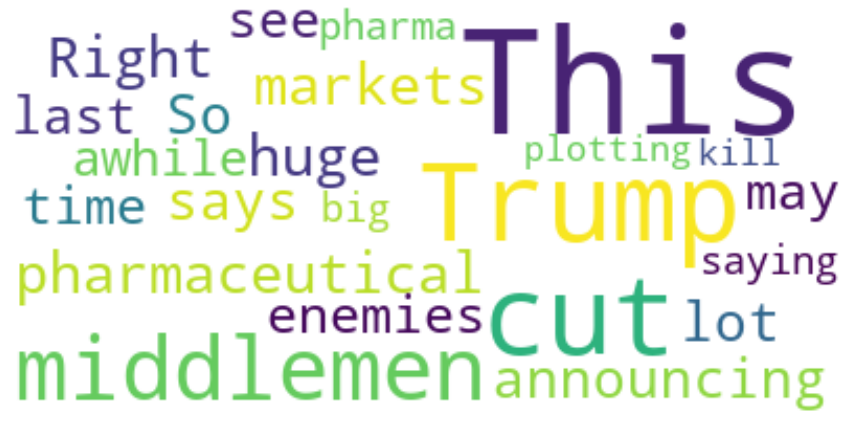
| Fig4. Wordcloud of a specific Twitter User about Trump|
Likewise, you can use any cases to know what people think and contact them via Twitter, changing ‘KEYWORDS’ and ‘THRESHOLD’.
Leave a comment