
Deep Learning Applications in Computer Vision
Applications in Computer Vision
Even though there are many challenging problems in computer vision, I would like to categorize them into 8 so far and introduce important papers for each type.
1. Image Classification
Image classification is the task of classifying image into one of the pre-defined categories. The most famous exmaple is cat or dog classification. The main point is to distinguish the features of image. AlexNet, ResNet, and VGG are popular techniques.

Papers:
ImageNet Classification With Deep Convolutional Neural Networks
Deep Residual Learning for Image Recognition
2. Object Detection
Object detection is the task of classification with localization. Using a bounding box around the object, objects in different categories are detected. There are two evalution methods for this techniue; mAP for classification and IoU for localization. Due to the imbalance of dataset, average precision (AP) via maximized area under the precision-recall (just like AUC through ROC) can be averaged over all categories. This categorical mean of AP is called mAP (mean Averaged Precision). Thus, mAP is evaluation metric for classification while intersection over unit (IoU) is one for localization if a bounding box is localized well around the object.

There are 2 types of detector; 1-stage detector (R-CNN family) and 2-stage detector (YOLO or SSD family). 1-sage detector works for region proporal and classification simultaneously by feature extraction while 2-stage dector works for them sequentially by selective search. For training time, 1-stage detector has faster trend than 2-stage, but 2-stage detector has lower localization error.
Papers:
Selective Search for Object Recognition
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
You Only Look Once: Unified, Real-Time Object Detection
3. Object Segmentation
Object segmentation is the task of object detection where a drawing line is around each detected object. While object detection identifies objects through a bounding box, object segmentation identifies relevant pixels that belong to an object. There are semantic segmentation and instance segmentation. Instead of treating each pixel that belongs to an object categories (semantic), instance segmentation treats each pixel that belongs to an object instance.
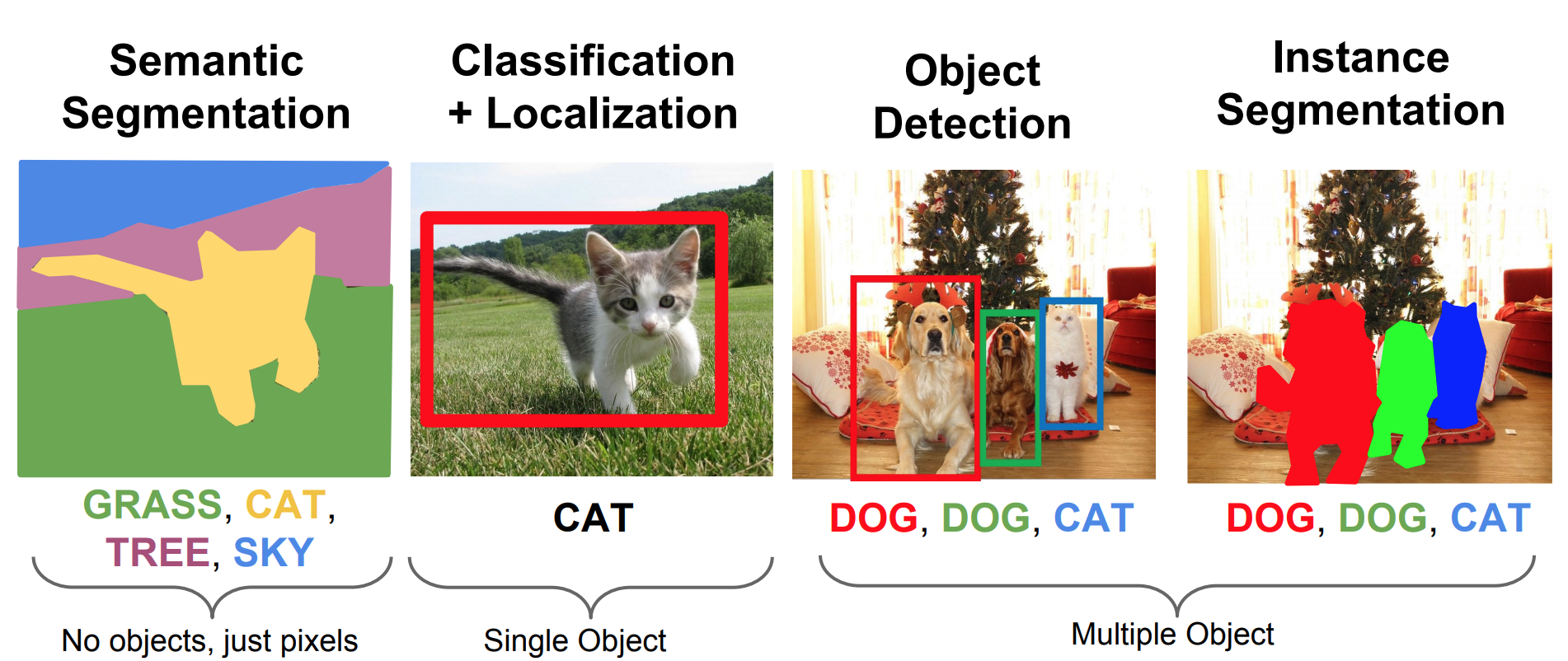
Due to cruciality of every pixel information (especially in each object boundary), downsampling (Conv+Pool) and upsampling (Transpose Conv) are popularly used rather than fully connected layers that causes loss of spatial information.
Papers:
Simultaneous Detection and Segmentation
Fully Convolutional Networks for Semantic Segmentation
SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
4. Object Tracking
Object tracking is the task of taking an initial set of object detections with localization, creating a unique ID for each of the initial sets, and then tracking each in frames of a video.
Centroid based ID assignment:
- Take an initial set of object detection with an input set of bounding box coordinates.
- Create a unique ID for each initial detection.
- Assign the unique ID to the obect that has the nearest centroid of bounding box in the next frame (tracking).
In this case, it is possible that assignment of ID could be switched when objects overlap. So, Kalman filter can be used to track based on moving speed and direction of object.
Papers:
Simple Online and Realtime Tracking
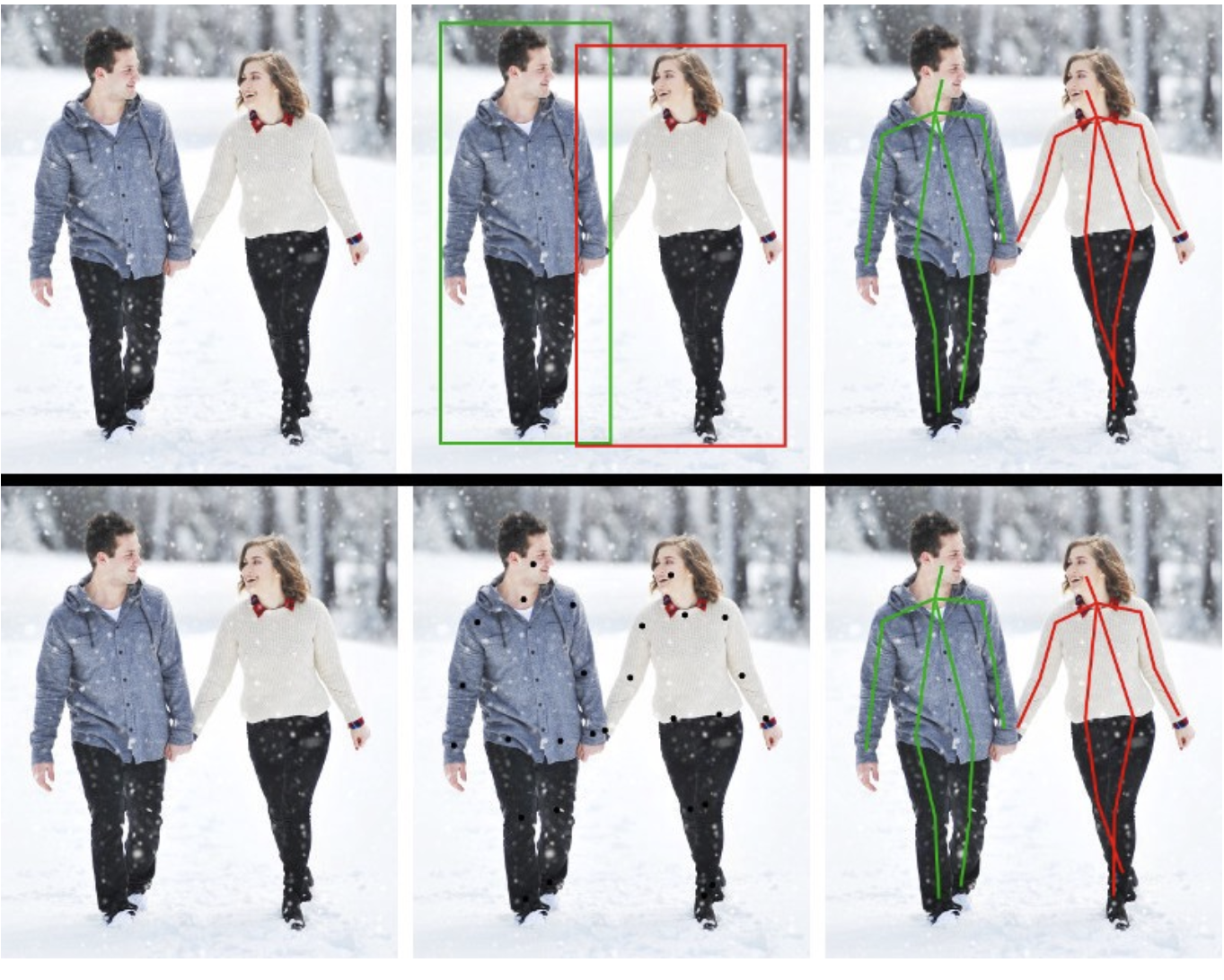
5. Pose Estimation
Pose Estimation is the task of identifying, locating, and tracking a number of keypoints on objects. Depending on dimension and number of points (keypoints), a point of body parts can be estimated based on regression loss. For instance, suppose that number of keypoints is set up 18. 2D pose estimation is based on \((x,y)\) coordinates for each joint (similarly, 3D pose estimation is based on \((x,y,z)\)). Then, in 2D, we have \((x_0,y_0)\), \((x_1,y_1)\), …, \((x_{17},y_{17})\). These points are estimated and optimized. Pose Estimation is heavily used in action recognition, animation, gaming, etc.

The top-down approach starts by identifying and localizing each object instance with a bounding box. Then, estimating is executed for the pose of the object. The bottom-up approach starts by localizing identity-free semantic entities, then grouping them into person instances.
6. Image Generation with GAN
There are various applications in GAN; face generation which outputs plausible photos from the actual existing photos, photo inpainting which performs plausible photos by filling in an area of a photograph that was removed, super resolution which is a technique to generate images with higher pixel resolution, etc.



GAN has two sub-models: a generator and a discriminator. A generator creates new plausible examples from the given domain against a discriminator which classifies if an instance is fake or real. That adversarial relationship improves quality of the output.
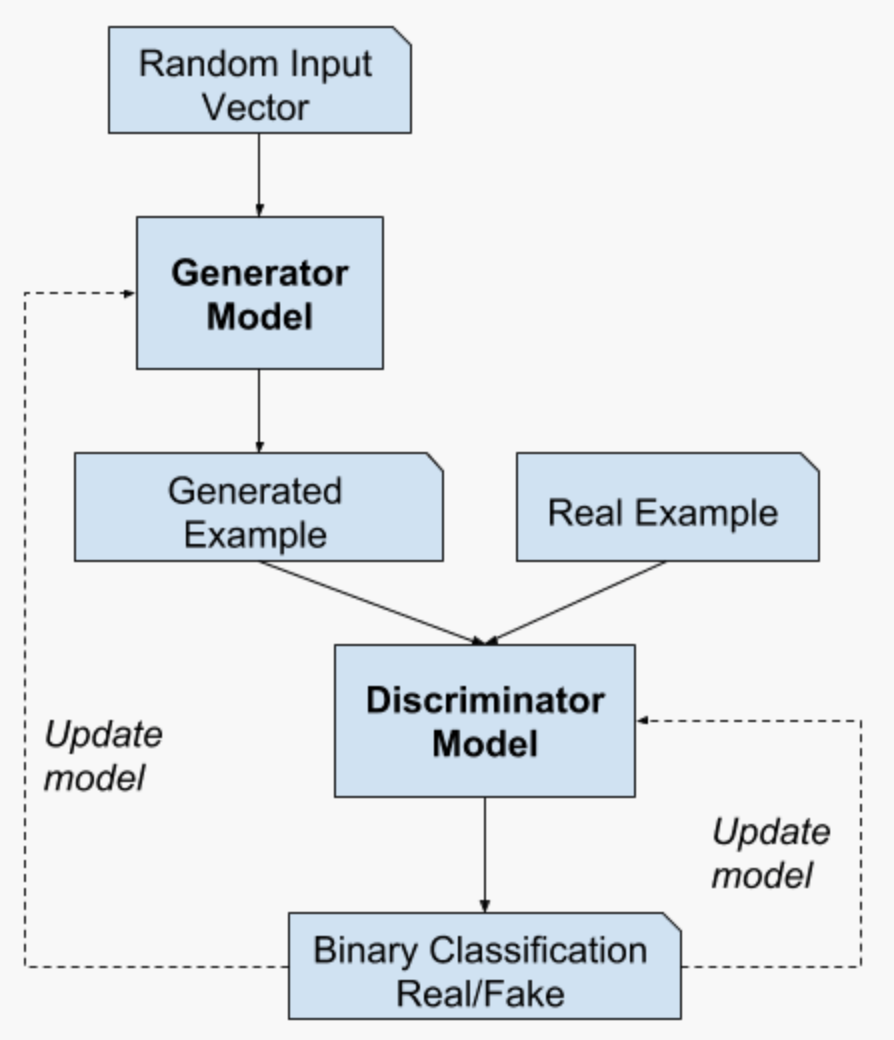
A generator takes a vector randomly drawn from Gaussian distribution as input and generates a sample. A discriminator takes the sample with real ones and predicts a binary class label of real or fake (generated sample). From this process, the generator and discriminator play two-player minimax game with value function, finding the features that generally appear in the problem domain and fitting output vector space to the statistical latent space. This zero-sum game improves quality of the generated sample (50% for both real and fake).
Papers:
Generative Adversarial Networks
Pixel Recurrent Neural Networks
Image Inpainting for Irregular Holes Using Partial Convolutions
Highly Scalable Image Reconstruction using Deep Neural Networks with Bandpass Filtering
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
Deep Laplacian Pyramid Networks for Fast and Accurate Super-Resolution
7. Image Captioning
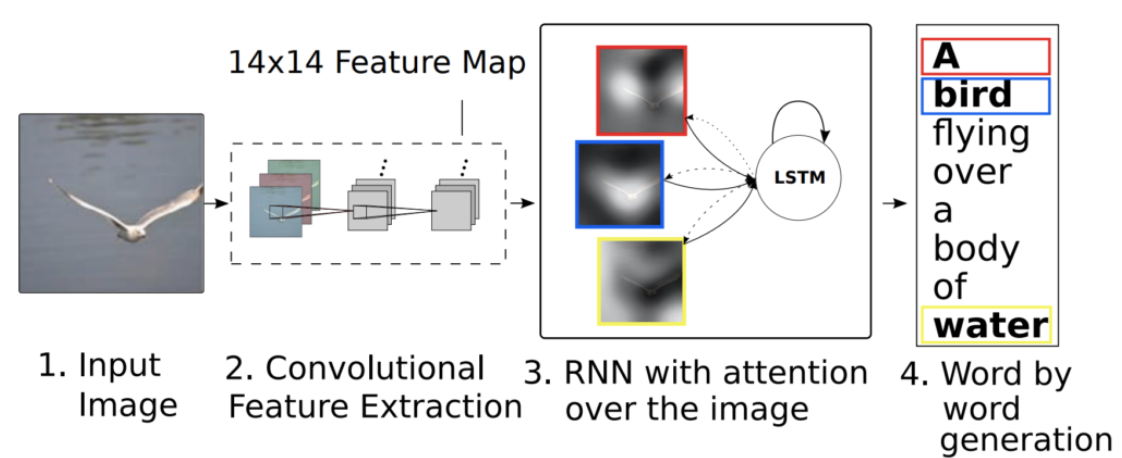
Image Captioning is the task of generating a textual description for given images. The model can take two inputs; an image for CNN and texts in a sequence for RNN. Extracting the important features from an image via CNN and using RNN over the image to generate the textual sentence for the image description.

Figure 10 shows how image captioning works graphically.
8. Anomaly Detection
Anomaly detection is the task of identifying rare patterns or observations by differing significantly from the majority of the data. Depending on data with annotation, approach would vary.
- Images with labels (supervised)
- Images only with labels for nomal data (semi-supervised)
- No label (unsupervised)
In the case of supervised learning, data imbalance of abnomal data is challenging. In the case of semi-supervised learning, learning the important features from the labeled data, so this method is limited to only including labeled normal samples and disregards the unlabeled ones. The unsupervised learning case for anomaly detection is based on two models; autoencoder and CNN. In either case, feature extraction is needed for which features has to be investigated for anomaly detection; Many algorithms of reducing number of dimensions are used. Edge detection for images, fast Fourier transform (FFT) for sounds, or discrete cosine transform (DCT) for other cases. Moreover, k-means clustering and principal component analysis (PCA) can help grouping and reducing dimensions. For autoencoder, it internally compresses the data into a latent-space and reconstruct the input data from the latent representation with regression loss.
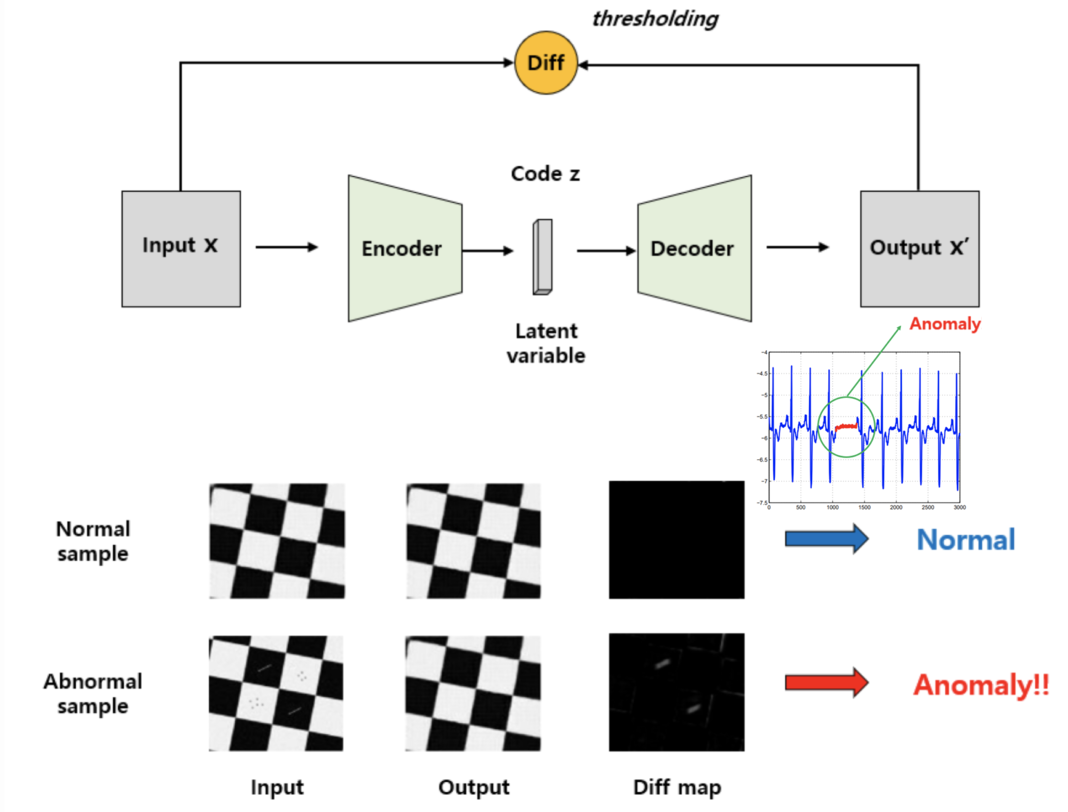
Papers:
Improving Unsupervised Defect Segmentation by Applying Structural Similarity To Autoencoders
Deep Autoencoding Models for Unsupervised Anomaly Segmentation in Brain MR Images
Leave a comment