
Data Matching (Recordlinkage and Fuzzymatcher)
1. Introduction
Record Linkage aka data matching/merging is to join the information from a variety of data sources. The recordlinkage and fuzzymaker are used for process of joining two data sets when they don’t have a common unique identifier.
This problem is a common business challenge and difficult to solve in a systematic way due to the tremendous amount of data sets. A naive approach using vlookup function in Excel requests a lot of human intervention. To reduce that, fuzzymatcher and recordlinkage can be used.
fuzzymatcherallows us to match two pandas DataFrames using sqlite3 for finding potential matches and probabilistic record linkage for scoring those matches.recordlinkageis a library to link records in or between data sources.
2. Problem
If trying to merge two datasets that comes from two separate sources, you must have some challenge of removing duplicates; like the contents are the same but a machine could not recognize that they are the same. For instance, a machine cannot recognize the duplicates that do not match exactly.
When machine recognizes that the data match:

| Fig1. Deterministic Matching |
This is called Deterministic matching. However, it happens that a part of data is mistyped or missing. Then, we use probability to match (Probabilistic matching). Using string distance algorithms like Levenshtein, Damerau-Levenshtein, Jaro-Winkler, q-gram, and cosine, we score a match to see how such matching is suitable.
| Fig2. Data Linkage/Matching Analogy |
Through the data-matching, Duplicates in the data can be eliminated.
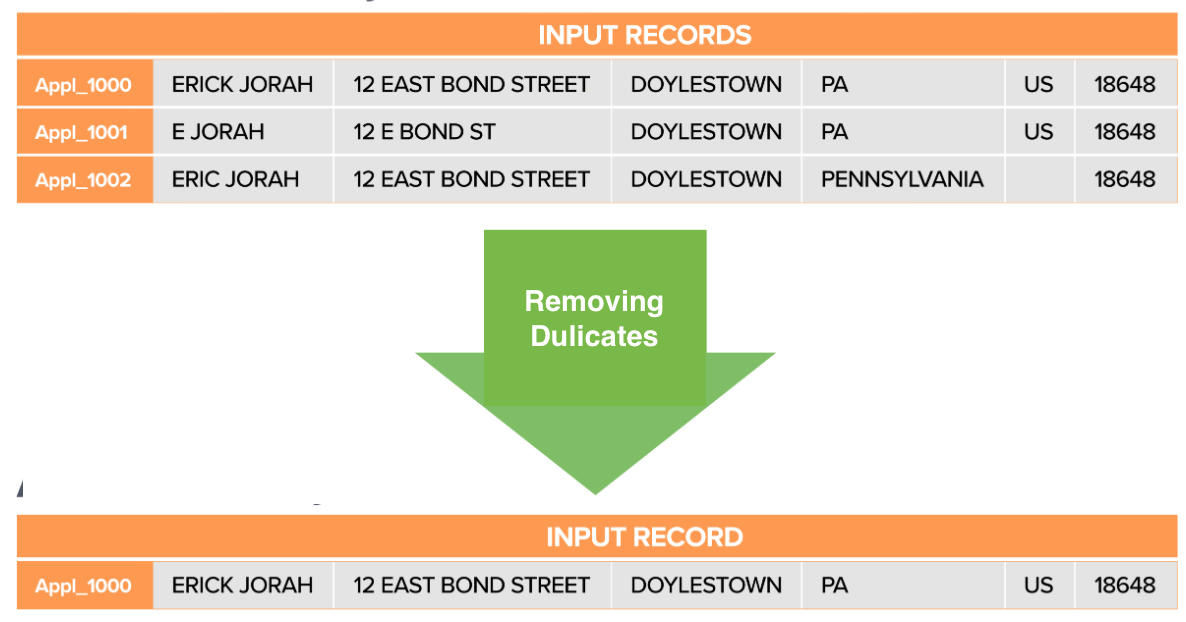
| Fig3. Eliminating Duplicates (Deduplication) |
The vlookup function in Excel requests exhaustive work, so using fuzzymatcher or recordlinkage is recommended.
3. Data
For exploring the data matching, US hospital data was used for the following challenges:
- Similar names of hospitals: to know they are different or the same (Saint Lukes, Saint Mary, etc.)
- Unclear addresses of hospitals: some hospitals located in urban areas have ambiguous addresses.
- A lot of assosiated clinics or facilities: hospitals tend to have many clinics and facilities associated and related nearby.
- Name changes: name changes of hospitals are common.
- Scalability: a thousands of medical facilities in the US is hard to scale.
The full data sets are available: Medicare.gov and CMS.gov. I used the cleaned version available here.
3.1. Importing packages
import pandas as pd
from pathlib import Path
import fuzzywuzzy as fw # works at python 3.6 ver.
import fuzzymatcher as fm # works at python 3.6 ver.
import recordlinkage as rl# works at python 3.6 ver.
4. Fuzzymatcher
4.1. Loading the data
hospital_accounts = pd.read_csv(
'hospital_account_info.csv'
)
hospital_reimbursement = pd.read_csv(
'hospital_reimbursement.csv'
)
US hospital account Data:
hospital_accounts.head(2)
| Facility Name | Address | City | State | ZIP Code | County Name | Phone Number | Hospital Type | Hospital Ownership | Acct_Name_Lookup | |
|---|---|---|---|---|---|---|---|---|---|---|
| Account_Num | ||||||||||
| 10605 | SAGE MEMORIAL HOSPITAL | STATE ROUTE 264 SOUTH 191 | GANADO | AZ | 86505 | APACHE | (928) 755-4541 | Critical Access Hospitals | Voluntary non-profit - Private | SAGE MEMORIAL HOSPITAL_STATE ROUTE 264 SOUTH 1... |
| 24250 | WOODRIDGE BEHAVIORAL CENTER | 600 NORTH 7TH STREET | WEST MEMPHIS | AR | 72301 | CRITTENDEN | (870) 394-4113 | Psychiatric | Proprietary | WOODRIDGE BEHAVIORAL CENTER_600 NORTH 7TH STRE... |
US reimbursement Data:
hospital_reimbursement.head(2)
| Provider Name | Provider Street Address | Provider City | Provider State | Provider Zip Code | Total Discharges | Average Covered Charges | Average Total Payments | Average Medicare Payments | Reimbursement_Name_Lookup | |
|---|---|---|---|---|---|---|---|---|---|---|
| Provider_Num | ||||||||||
| 839987 | SOUTHEAST ALABAMA MEDICAL CENTER | 1108 ROSS CLARK CIRCLE | DOTHAN | AL | 36301 | 118 | 20855.61 | 5026.19 | 4115.52 | SOUTHEAST ALABAMA MEDICAL CENTER_1108 ROSS CLA... |
| 519118 | MARSHALL MEDICAL CENTER SOUTH | 2505 U S HIGHWAY 431 NORTH | BOAZ | AL | 35957 | 43 | 13289.09 | 5413.63 | 4490.93 | MARSHALL MEDICAL CENTER SOUTH_2505 U S HIGHWAY... |
4.2. Joining the data
Since the columns have different names, we need to define which columns to match for the left and right DataFrames. In this case, the ‘hospital_accounts’ will be the left and the ‘hospital_reimbursement’ will be the right.
# Columns to match on from df_left
left_on = ["Facility Name", "Address", "City", "State"]
# Columns to match on from df_right
right_on = [
"Provider Name", "Provider Street Address", "Provider City",
"Provider State"
]
Using function fuzzy_left_join(), I let the fuzzymatcher work on matching.
# Now perform the match
# It will take several minutes to run on this data set
matched_results = fm.fuzzy_left_join(hospital_accounts,
hospital_reimbursement,
left_on,
right_on,
left_id_col='Account_Num',
right_id_col='Provider_Num')
NOTE For over 10 million combinations of the dataset,
fuzzymatcherfinds the best match for each combination, so it takes a while.
The DataFrame ‘matched_results’ contains all the data linked together as well as ‘best_match_score’ which shows the measure of the matching.
matched_results.head(2)
| best_match_score | __id_left | __id_right | Account_Num | Facility Name | Address | City | State | ZIP Code | County Name | ... | Provider_Num | Provider Name | Provider Street Address | Provider City | Provider State | Provider Zip Code | Total Discharges | Average Covered Charges | Average Total Payments | Average Medicare Payments | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -0.746613 | 10605 | 643595 | 10605 | SAGE MEMORIAL HOSPITAL | STATE ROUTE 264 SOUTH 191 | GANADO | AZ | 86505 | APACHE | ... | 643595 | TYLER MEMORIAL HOSPITAL | 5950 STATE ROUTE 6 WEST | TUNKHANNOCK | PA | 18657 | 18 | 20482.94 | 5783.22 | 4929.22 |
| 234 | -0.609873 | 24250 | 426767 | 24250 | WOODRIDGE BEHAVIORAL CENTER | 600 NORTH 7TH STREET | WEST MEMPHIS | AR | 72301 | CRITTENDEN | ... | 426767 | CRISP REGIONAL HOSPITAL | 902 7TH STREET NORTH | CORDELE | GA | 31015 | 18 | 14655.94 | 5680.28 | 4899.39 |
4.3. Best and Worst Matches
The columns are rearranged for readability. The following data represent the top 3 best matches and the worst 3
# Reorder the columns to make viewing easier
cols = [
"best_match_score", "Facility Name", "Provider Name", "Address", "Provider Street Address",
"Provider City", "City", "Provider State", "State"
]
# Check the top 3 best matches
rearranged_best_matches=matched_results[cols].sort_values(by=['best_match_score'], ascending=False)
rearranged_best_matches.head(3)
| best_match_score | Facility Name | Provider Name | Address | Provider Street Address | Provider City | City | Provider State | State | |
|---|---|---|---|---|---|---|---|---|---|
| 78037 | 3.090931 | RARITAN BAY MEDICAL CENTER PERTH AMBOY DIVISION | RARITAN BAY MEDICAL CENTER PERTH AMBOY DIVISION | 530 NEW BRUNSWICK AVE | 530 NEW BRUNSWICK AVE | PERTH AMBOY | PERTH AMBOY | NJ | NJ |
| 533154 | 2.799072 | ROBERT WOOD JOHNSON UNIVERSITY HOSPITAL | ROBERT WOOD JOHNSON UNIVERSITY HOSPITAL | ONE ROBERT WOOD JOHNSON PLACE | ONE ROBERT WOOD JOHNSON PLACE | NEW BRUNSWICK | NEW BRUNSWICK | NJ | NJ |
| 78626 | 2.785132 | AVERA MCKENNAN HOSPITAL & UNIVERSITY HEALTH CE... | AVERA MCKENNAN HOSPITAL & UNIVERSITY HEALTH CE... | 1325 S CLIFF AVE POST OFFICE BOX 5045 | 1325 S CLIFF AVE POST OFFICE BOX 5045 | SIOUX FALLS | SIOUX FALLS | SD | SD |
# Check the worst 3 matches
rearranged_worst_matches=matched_results[cols].sort_values(by=['best_match_score'],
ascending=True)
rearranged_worst_matches.head(3)
# You can also use `tail()` from 'rearranged_best_matches'.
| best_match_score | Facility Name | Provider Name | Address | Provider Street Address | Provider City | City | Provider State | State | |
|---|---|---|---|---|---|---|---|---|---|
| 426392 | -2.268231 | CENTRO MEDICO WILMA N VAZQUEZ | BAPTIST MEDICAL CENTER EAST | CARR. 2 KM 39.5 ROAD NUMBER 2 BO ALGARROBO | 400 TAYLOR ROAD | MONTGOMERY | VEGA BAJA | AL | PR |
| 83137 | -2.124071 | DOCTOR CENTER HOSPITAL SAN FERNANDO DE LA CARO... | OVERLAKE HOSPITAL MEDICAL CENTER | EDIF JESUS T PINEIRO AVE FERNANDEZ JUNCOS BO P... | 1035-116TH AVE NE | BELLEVUE | CAROLINA | WA | PR |
| 42545 | -2.106746 | HOSPITAL ONCOLOGICO DR ISAAC GONZALEZ MARTINEZ | SCRIPPS MERCY HOSPITAL | BO. MONACILLOS CARR 22 CENTRO MEDICO DE PUERTO... | 4077 5TH AVE | SAN DIEGO | SAN JUAN | CA | PR |
As you can see, ‘Provider State’ and ‘State’ are different; meaning that some hospitals at different states (AL, WA, or CA) are mismatched with some hospitals at PR (Puerto Rico).
Check the Threshold
Now let’s find the threshold to collect the acceptible data that properly matched. When we see some of the matches with their scores $\leq$ 75:
# Look at the matches below 0.75
matched_results[cols].query("best_match_score <= .75").sort_values(
by=['best_match_score'], ascending=False).head(10)
| best_match_score | Facility Name | Provider Name | Address | Provider Street Address | Provider City | City | Provider State | State | |
|---|---|---|---|---|---|---|---|---|---|
| 179656 | 0.745897 | HCA HOUSTON HEALTHCARE KINGWOOD | KINGWOOD MEDICAL CENTER | 22999 US HWY 59 | 22999 US HWY 59 | KINGWOOD | KINGWOOD | TX | TX |
| 147070 | 0.744798 | ADVENTIST HEALTH SONORA | SONORA REGIONAL MEDICAL CENTER | 1000 GREENLEY ROAD | 1000 GREENLEY ROAD | SONORA | SONORA | CA | CA |
| 550827 | 0.739983 | ADVENTHEALTH MANCHESTER | MEMORIAL HOSPITAL | 210 MARIE LANGDON DRIVE | 210 MARIE LANGDON DRIVE | MANCHESTER | MANCHESTER | KY | KY |
| 404399 | 0.739409 | UPMC KANE | KANE COMMUNITY HOSPITAL | 4372 ROUTE 6 | 4372 ROUTE 6 | KANE | KANE | PA | PA |
| 399780 | 0.738336 | MARSHFIELD MEDICAL CENTER - RICE LAKE | LAKEVIEW MEDICAL CENTER | 1700 WEST STOUT STREET | 1700 WEST STOUT STREET | RICE LAKE | RICE LAKE | WI | WI |
| 477383 | 0.736923 | TRINITY BETTENDORF | UNITY POINT HEALTH TRINITY | 4500 UTICA RIDGE ROAD | 4500 UTICA RIDGE ROAD | BETTENDORF | BETTENDORF | IA | IA |
| 160318 | 0.728097 | RUSH COPLEY MEDICAL CENTER | COPLEY MEMORIAL HOSPITAL | 2000 OGDEN AVENUE | 2000 OGDEN AVENUE | AURORA | AURORA | IL | IL |
| 555173 | 0.724772 | UNITYPOINT HEALTH - KEOKUK | KEOKUK AREA HOSPITAL | 1600 MORGAN STREET | 1600 MORGAN STREET | KEOKUK | KEOKUK | IA | IA |
| 368685 | 0.722856 | CALIFORNIA PACIFIC MEDICAL CTR-DAVIES CAMPUS HOSP | CALIFORNIA PACIFIC MEDICAL CTR-PACIFIC CAMPUS ... | 601 DUBOCE AVENUE | 2333 BUCHANAN STREET | SAN FRANCISCO | SAN FRANCISCO | CA | CA |
| 431261 | 0.720821 | KANSAS SPINE & SPECIALTY HOSPITAL, LLC | KANSAS HEART HOSPITAL | 3333 NORTH WEBB ROAD | 3601 NORTH WEBB ROAD | WICHITA | WICHITA | KS | KS |
It shows that the data becomes more ambiguous below 0.75. The CALIFORNIA PACIFIC MEDICAL CTR-DAVIES CAMPUS HOSP is different from CALIFORNIA PACIFIC MEDICAL CTR-PACIFIC CAMPUS.
By checking your data, you need to find and set the proper threshold for collecting data.
Overall, fuzzymatcher is a useful tool to have for medium sized data sets (around 10,000) due to its computational time. However, it is easy to use.
5. Recordlinkage
Record Linkage Toolkit can clean, standardize data, and score similarity of data like fuzzymatcher, but it has additional capabilities:
- makes pairs of data by ‘blocking’ (
block()) to limit the pool of potential matches and ‘grouping’ (sortedneighbourhood()) to cover the data with minor spelling mistakes. - compares data with similarity scores for different types of data.
- provides Supervised and unsupervised classification algorithms for classifying data.
The trade-off is that it is a little more complicated to wrangle the results in order to do further validation. However, the steps are relatively standard pandas commands so do not let that intimidate you.
5.1. Loading the data with index_col
It needs to set the ‘index_col’ argument for indexing
# Re-read in the data using the index_col
hospital_accounts = pd.read_csv(
'hospital_account_info.csv',
index_col='Account_Num'
)
hospital_reimbursement = pd.read_csv(
'hospital_reimbursement.csv',
index_col='Provider_Num'
)
hospital_accounts.head(2)
| Facility Name | Address | City | State | ZIP Code | County Name | Phone Number | Hospital Type | Hospital Ownership | |
|---|---|---|---|---|---|---|---|---|---|
| Account_Num | |||||||||
| 10605 | SAGE MEMORIAL HOSPITAL | STATE ROUTE 264 SOUTH 191 | GANADO | AZ | 86505 | APACHE | (928) 755-4541 | Critical Access Hospitals | Voluntary non-profit - Private |
| 24250 | WOODRIDGE BEHAVIORAL CENTER | 600 NORTH 7TH STREET | WEST MEMPHIS | AR | 72301 | CRITTENDEN | (870) 394-4113 | Psychiatric | Proprietary |
hospital_reimbursement.head(2)
| Provider Name | Provider Street Address | Provider City | Provider State | Provider Zip Code | Total Discharges | Average Covered Charges | Average Total Payments | Average Medicare Payments | |
|---|---|---|---|---|---|---|---|---|---|
| Provider_Num | |||||||||
| 839987 | SOUTHEAST ALABAMA MEDICAL CENTER | 1108 ROSS CLARK CIRCLE | DOTHAN | AL | 36301 | 118 | 20855.61 | 5026.19 | 4115.52 |
| 519118 | MARSHALL MEDICAL CENTER SOUTH | 2505 U S HIGHWAY 431 NORTH | BOAZ | AL | 35957 | 43 | 13289.09 | 5413.63 | 4490.93 |
5.2. Blocking
Blocking is nothing but a limiter of the size of comparisons. For instance, we want to compare the only hospitals that are in the same state. We can use this knowledge to setup a block on the state columns.
This will speed up the process, but adding some flexibility for minor spelling mistakes is important. Using SortedNeighborhood() function to clean the data
# Build the indexer
indexer = rl.Index()
# Can use full or block
indexer.full()
indexer.block(left_on='State', right_on='Provider State')
# Use sortedneighbor as a good option if data is not clean
indexer.sortedneighbourhood(left_on='State', right_on='Provider State')
It may toss a warning of large number of data. With the recordlinkage, we have some flexibility to influence how many pairs are evaluated. By using full indexer all potential pairs are evaluated (which we know is over 14M pairs). I will come back to some of the other options in a moment. Let’s continue with the full index and see how it performs.
The next step is to build up all the potential candidates to check:
candidates = indexer.index(hospital_accounts, hospital_reimbursement)
# Let's see how many matches we want to do
print(len(candidates))
14399283
This quick check just confirmed the total number of comparisons. With the block on state, the 14,399,283 candidates will be filtered to only include those where the state values are the same. It may take longer to take care of minor spelling mistakes, but it is a reasonable trade-off.
5.3. Comparing
Now that we have defined the left and right data sets and all the candidates, we can define how we want to perform the comparison logic using the Compare() function
# Takes 3 minutes using the full index.
# 14s using sorted neighbor
# 7s using blocking
compare = rl.Compare()
compare.exact('City', 'Provider City', label='City')
compare.string('Facility Name',
'Provider Name',
threshold=0.85,
label='Hosp_Name')
compare.string('Address',
'Provider Street Address',
method='jarowinkler',
threshold=0.85,
label='Hosp_Address')
features = compare.compute(candidates, hospital_accounts,
hospital_reimbursement)
We can define several options for how we want to compare the columns of data. In this specific example, we look for an exact match on the city. I have also shown some examples of string comparison along with the threshold and algorithm to use for comparison. In addition to these options, you can define your own or use numeric, dates and geographic coordinates. Refer to the documentation for more examples.
Regardless of which option you use, the result is a features DataFrame that looks like this:
features
| City | Hosp_Name | Hosp_Address | ||
|---|---|---|---|---|
| Account_Num | Provider_Num | |||
| 10605 | 537184 | 0 | 0.0 | 0.0 |
| 803181 | 0 | 0.0 | 0.0 | |
| 450616 | 0 | 0.0 | 0.0 | |
| 854377 | 0 | 0.0 | 0.0 | |
| 560361 | 0 | 0.0 | 0.0 | |
| ... | ... | ... | ... | ... |
| 70226 | 815904 | 0 | 0.0 | 0.0 |
| 746090 | 0 | 0.0 | 0.0 | |
| 193062 | 0 | 0.0 | 0.0 | |
| 834984 | 0 | 0.0 | 0.0 | |
| 365095 | 0 | 0.0 | 0.0 |
This DataFrame shows the results of all of the comparisons. There is one row for each row in the account and reimbursement DataFrames. The columns correspond to the comparisons we defined. 1 is a match and 0 is not.
5.4. Similarity Score
Given the large number of records with no matches, it is a little hard to see how many matches we might have. We can sum up the individual scores to see about the quality of the matches.
# What are the score totals?
features.sum(axis=1).value_counts().sort_index(ascending=False)
3.0 2285
2.0 451
1.0 7937
0.0 988187
dtype: int64
Now we know that there are 988,187 rows with no matching values whatsoever. 7,937 rows have at least one match, 451 have 2 and 2,285 have 3 matches.
To make the rest of the analysis easier, let’s get all the records with 2 or 3 matches and add a total score:
# Get the potential matches
potential_matches = features[features.sum(axis=1) > 1].reset_index()
potential_matches['Score'] = potential_matches.loc[:, 'City':'Hosp_Address'].sum(axis=1)
potential_matches.head()
| Account_Num | Provider_Num | City | Hosp_Name | Hosp_Address | Score | |
|---|---|---|---|---|---|---|
| 0 | 51216 | 268781 | 0 | 1.0 | 1.0 | 2.0 |
| 1 | 55272 | 556917 | 1 | 1.0 | 1.0 | 3.0 |
| 2 | 87807 | 854637 | 1 | 1.0 | 1.0 | 3.0 |
| 3 | 51151 | 783146 | 1 | 0.0 | 1.0 | 2.0 |
| 4 | 11740 | 260374 | 1 | 1.0 | 1.0 | 3.0 |
Here is how to interpret the table. For the first row, Account_Num 55,272 and Provider_Num 556,917 match on city, hospital name and hospital address.
Let’s look at these two and see how close they are:
hospital_accounts.loc[55272,:]
Facility Name SCOTTSDALE OSBORN MEDICAL CENTER
Address 7400 EAST OSBORN ROAD
City SCOTTSDALE
State AZ
ZIP Code 85251
County Name MARICOPA
Phone Number (480) 882-4004
Hospital Type Acute Care Hospitals
Hospital Ownership Proprietary
Name: 55272, dtype: object
hospital_reimbursement.loc[556917,:]
Provider Name SCOTTSDALE OSBORN MEDICAL CENTER
Provider Street Address 7400 EAST OSBORN ROAD
Provider City SCOTTSDALE
Provider State AZ
Provider Zip Code 85251
Total Discharges 62
Average Covered Charges 39572.2
Average Total Payments 6551.47
Average Medicare Payments 5451.89
Name: 556917, dtype: object
Those look like good matches.
5.5. Joining
Now that we know the matches, we need to wrangle the data to make it easier to review all the data together. I am going to make a concatenated name and address lookup for each of these source DataFrames.
# Add some convenience columns for comparing data
hospital_accounts['Acct_Name_Lookup'] = hospital_accounts[[
'Facility Name', 'Address', 'City', 'State'
]].apply(lambda x: '_'.join(x), axis=1)
hospital_reimbursement['Reimbursement_Name_Lookup'] = hospital_reimbursement[[
'Provider Name', 'Provider Street Address', 'Provider City',
'Provider State'
]].apply(lambda x: '_'.join(x), axis=1)
reimbursement_lookup = hospital_reimbursement[['Reimbursement_Name_Lookup']].reset_index()
account_lookup = hospital_accounts[['Acct_Name_Lookup']].reset_index()
account_lookup.head(2)
| Account_Num | Acct_Name_Lookup | |
|---|---|---|
| 0 | 10605 | SAGE MEMORIAL HOSPITAL_STATE ROUTE 264 SOUTH 1... |
| 1 | 24250 | WOODRIDGE BEHAVIORAL CENTER_600 NORTH 7TH STRE... |
reimbursement_lookup.head(2)
| Provider_Num | Reimbursement_Name_Lookup | |
|---|---|---|
| 0 | 839987 | SOUTHEAST ALABAMA MEDICAL CENTER_1108 ROSS CLA... |
| 1 | 519118 | MARSHALL MEDICAL CENTER SOUTH_2505 U S HIGHWAY... |
account_merge = potential_matches.merge(account_lookup, how='left')
account_merge.head()
| Account_Num | Provider_Num | City | Hosp_Name | Hosp_Address | Score | Acct_Name_Lookup | |
|---|---|---|---|---|---|---|---|
| 0 | 51216 | 268781 | 0 | 1.0 | 1.0 | 2.0 | ST FRANCIS MEDICAL CENTER_2400 ST FRANCIS DRIV... |
| 1 | 55272 | 556917 | 1 | 1.0 | 1.0 | 3.0 | SCOTTSDALE OSBORN MEDICAL CENTER_7400 EAST OSB... |
| 2 | 87807 | 854637 | 1 | 1.0 | 1.0 | 3.0 | ORO VALLEY HOSPITAL_1551 EAST TANGERINE ROAD_O... |
| 3 | 51151 | 783146 | 1 | 0.0 | 1.0 | 2.0 | ST. LUKE'S BEHAVIORAL HOSPITAL, LP_1800 EAST V... |
| 4 | 11740 | 260374 | 1 | 1.0 | 1.0 | 3.0 | SUMMIT HEALTHCARE REGIONAL MEDICAL CENTER_2200... |
The merge in the reimbursement data:
# Let's build a dataframe to compare
final_merge = account_merge.merge(reimbursement_lookup, how='left')
cols = [
'Account_Num', 'Provider_Num', 'Score', 'Acct_Name_Lookup',
'Reimbursement_Name_Lookup'
]
final_merge[cols].sort_values(by=['Account_Num', 'Score'], ascending=False)
| Account_Num | Provider_Num | Score | Acct_Name_Lookup | Reimbursement_Name_Lookup | |
|---|---|---|---|---|---|
| 2660 | 94995 | 825914 | 3.0 | CLAIBORNE MEDICAL CENTER_1850 OLD KNOXVILLE HI... | CLAIBORNE MEDICAL CENTER_1850 OLD KNOXVILLE HI... |
| 1975 | 94953 | 819181 | 3.0 | LAKE CHARLES MEMORIAL HOSPITAL_1701 OAK PARK B... | LAKE CHARLES MEMORIAL HOSPITAL_1701 OAK PARK B... |
| 1042 | 94943 | 680596 | 3.0 | VALLEY PRESBYTERIAN HOSPITAL_15107 VANOWEN ST_... | VALLEY PRESBYTERIAN HOSPITAL_15107 VANOWEN ST_... |
| 2305 | 94923 | 403151 | 3.0 | UNIVERSITY COLO HEALTH MEMORIAL HOSPITAL CENTR... | UNIVERSITY COLO HEALTH MEMORIAL HOSPITAL CENTR... |
| 2512 | 94887 | 752284 | 2.0 | NEW YORK-PRESBYTERIAN BROOKLYN METHODIST HOSPI... | NEW YORK METHODIST HOSPITAL_506 SIXTH STREET_B... |
| ... | ... | ... | ... | ... | ... |
| 2080 | 10165 | 188247 | 3.0 | UTAH VALLEY HOSPITAL_1034 NORTH 500 WEST_PROVO_UT | UTAH VALLEY HOSPITAL_1034 NORTH 500 WEST_PROVO_UT |
| 1825 | 10090 | 212069 | 3.0 | CANONSBURG GENERAL HOSPITAL_100 MEDICAL BOULEV... | CANONSBURG GENERAL HOSPITAL_100 MEDICAL BOULEV... |
| 2424 | 10043 | 140535 | 3.0 | BETH ISRAEL DEACONESS HOSPITAL - PLYMOUTH_275 ... | BETH ISRAEL DEACONESS HOSPITAL - PLYMOUTH_275 ... |
| 1959 | 10020 | 210657 | 3.0 | ST FRANCIS MEDICAL CENTER_309 JACKSON STREET_M... | ST FRANCIS MEDICAL CENTER_309 JACKSON STREET_M... |
| 1958 | 10020 | 121670 | 2.0 | ST FRANCIS MEDICAL CENTER_309 JACKSON STREET_M... | UNIVERSITY HEALTH CONWAY_4864 JACKSON STREET_M... |
6. Deduplicates Remover with Recordlinkage
Another additional uses of the Recordlinkage is for finding duplicate records in a data set. The process is very similar to matching except you pass match a single DataFrame against itself.
6.1. Loading the data
hospital_dupes = pd.read_csv(
'hospital_account_dupes.csv',
index_col='Account_Num')
hospital_dupes.head(2)
| Facility Name | Address | City | State | ZIP Code | County Name | Phone Number | Hospital Type | Hospital Ownership | |
|---|---|---|---|---|---|---|---|---|---|
| Account_Num | |||||||||
| 71730 | SAGE MEMORIAL HOSPITAL | STATE ROUTE 264 SOUTH 191 | GANADO | AZ | 86505 | APACHE | (928) 755-4541 | Critical Access Hospitals | Voluntary non-profit - Private |
| 70116 | WOODRIDGE BEHAVIORAL CENTER | 600 NORTH 7TH STREET | WEST MEMPHIS | AR | 72301 | CRITTENDEN | (870) 394-4113 | Psychiatric | Proprietary |
6.2. Blocking
Then create our indexer with a sortedneighbourhood block on State .
# Deduping follows the same process, you just use 1 single dataframe
dupe_indexer = rl.Index()
dupe_indexer.sortedneighbourhood(left_on='State')
dupe_candidate_links = dupe_indexer.index(hospital_dupes)
6.3. Comparing
We should check for duplicates based on city, name and address:
# Comparison step
compare_dupes = rl.Compare()
compare_dupes.string('City', 'City', threshold=0.85, label='City')
compare_dupes.string('Phone Number',
'Phone Number',
threshold=0.85,
label='Phone_Num')
compare_dupes.string('Facility Name',
'Facility Name',
threshold=0.80,
label='Hosp_Name')
compare_dupes.string('Address',
'Address',
threshold=0.85,
label='Hosp_Address')
dupe_features = compare_dupes.compute(dupe_candidate_links, hospital_dupes)
Because we are only comparing with a single DataFrame, the resulting DataFrame has an ‘Account_Num_1’ and ‘Account_Num_2’:
dupe_features
| City | Phone_Num | Hosp_Name | Hosp_Address | ||
|---|---|---|---|---|---|
| Account_Num_1 | Account_Num_2 | ||||
| 26270 | 28485 | 0.0 | 0.0 | 0.0 | 0.0 |
| 30430 | 0.0 | 0.0 | 0.0 | 0.0 | |
| 43602 | 0.0 | 0.0 | 0.0 | 0.0 | |
| 59585 | 28485 | 0.0 | 0.0 | 0.0 | 0.0 |
| 30430 | 0.0 | 0.0 | 0.0 | 0.0 | |
| ... | ... | ... | ... | ... | ... |
| 64029 | 38600 | 0.0 | 0.0 | 0.0 | 0.0 |
| 35413 | 0.0 | 0.0 | 0.0 | 0.0 | |
| 81525 | 0.0 | 0.0 | 0.0 | 0.0 | |
| 82916 | 0.0 | 0.0 | 0.0 | 0.0 | |
| 18907 | 0.0 | 0.0 | 0.0 | 0.0 |
6.4. Similarity Score
dupe_features.sum(axis=1).value_counts().sort_index(ascending=False)
3.0 7
2.0 206
1.0 7859
0.0 973205
dtype: int64
potential_dupes = dupe_features[dupe_features.sum(axis=1) > 2].reset_index()
potential_dupes['Score'] = potential_dupes.loc[:, 'City':'Hosp_Address'].sum(axis=1)
potential_dupes.sort_values(by=['Score'], ascending=True)
| Account_Num_1 | Account_Num_2 | City | Phone_Num | Hosp_Name | Hosp_Address | Score | |
|---|---|---|---|---|---|---|---|
| 0 | 28494 | 37949 | 1.0 | 1.0 | 0.0 | 1.0 | 3.0 |
| 1 | 74835 | 77000 | 1.0 | 1.0 | 0.0 | 1.0 | 3.0 |
| 2 | 24549 | 28485 | 1.0 | 1.0 | 0.0 | 1.0 | 3.0 |
| 3 | 70366 | 52654 | 1.0 | 1.0 | 0.0 | 1.0 | 3.0 |
| 4 | 61685 | 24849 | 1.0 | 1.0 | 0.0 | 1.0 | 3.0 |
| 5 | 51567 | 41166 | 1.0 | 1.0 | 1.0 | 0.0 | 3.0 |
| 6 | 26495 | 41079 | 1.0 | 1.0 | 0.0 | 1.0 | 3.0 |
These 7 records are potentially duplicates; having a high likelihood of being duplicated. Let’s look at them more deeply:
# Take a look at one of the potential duplicates
hospital_dupes[hospital_dupes.index.isin([51567, 41166])]
| Facility Name | Address | City | State | ZIP Code | County Name | Phone Number | Hospital Type | Hospital Ownership | |
|---|---|---|---|---|---|---|---|---|---|
| Account_Num | |||||||||
| 41166 | ST VINCENT HOSPITAL | 835 S VAN BUREN ST | GREEN BAY | WI | 54301 | BROWN | (920) 433-0111 | Acute Care Hospitals | Voluntary non-profit - Church |
| 51567 | SAINT VINCENT HOSPITAL | 835 SOUTH VAN BUREN ST | GREEN BAY | WI | 54301 | BROWN | (920) 433-0112 | Acute Care Hospitals | Voluntary non-profit - Church |
Such potential duplicates can be confirmed with further checks. Their names and addresses are similar and their phone numbers are off by one digit.
As you can see, this method can be a powerful and relatively easy tool to inspect your data and check for duplicate records.
7. Summary
Matching/Linking different datasets on text fields like names and addresses is a common challenge in data processing. This article provided two useful data linkage packages to match two data from separate sources.
The fuzzymatcher uses sqlite 3 to simply match two pandas DataFrames together, based on probabilistic scoring. If you have a larger data set or need to use more complex matching logic, then the Recordlinkage could be a better tool for cleaning duplicates and joining data.
Leave a comment