
Demystifying Regularization
Regularization
Before discussing about regularization, we’ll do a quick recap on the notion of overfitting and the bias-variance tradeoff.
Overfitting: So what is overfitting? Well, to put it in more simple terms it’s when we built a model that is too complex that it matches the training data “too closely” or we can say that the model has started to learn not only the signal, but also the noise in the data. The result of this is that our model will do well on the training data, but won’t generalize to out-of-sample data, data that we have not seen before.
Bias-Variance tradeoff: When we discuss prediction models, prediction errors can be decomposed into two main subcomponents we care about: error due to “bias” and error due to “variance”. Understanding these two types of error can help us diagnose model results and avoid the mistake of over/under fitting. A typical graph of discussing this is shown below:
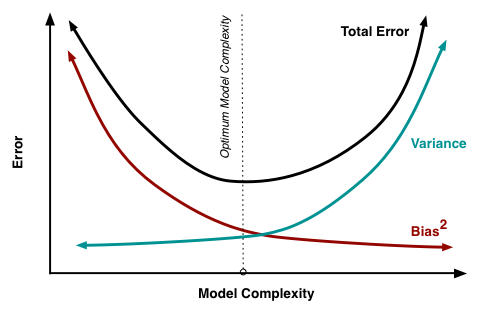
| Fig1. Bias-variance tradeoff|
- Bias: The red line, measures how far off in general our models’ predictions are from the correct value. Thus as our model gets more and more complex we will become more and more accurate about our predictions (Error steadily decreases).
- Variance: The cyan line, measures how different can our model be from one to another, as we’re looking at different possible data sets. If the estimated model will vary dramatically from one data set to the other, then we will have very erratic predictions, because our prediction will be extremely sensitive to what data set we obtain. As the complexity of our model rises, variance becomes our primary concern.
When creating a model, our goal is to locate the optimum model complexity. If our model complexity exceeds this sweet spot, we are in effect overfitting our model; while if our complexity falls short of the sweet spot, we are underfitting the model. With all of that in mind, the notion of regularization is simply a useful technique to use when we think our model is too complex (models that have low bias, but high variance). It is a method for “constraining” or “regularizing” the size of the coefficients (“shrinking” them towards zero). The specific regularization techniques we’ll be discussing are Ridge Regression and Lasso Regression.
For those interested, the following link contains a nice infogprahics on Bias-Variance Tradeoff. Blog: Bias-Variance Tradeoff Infographic
# code for loading the format for the notebook
import os
# path : store the current path to convert back to it later
path = os.getcwd()
os.chdir(os.path.join('..', 'notebook_format'))
from formats import load_style
load_style(plot_style = False)
os.chdir(path)
# 1. magic for inline plot
# 2. magic to print version
# 3. magic so that the notebook will reload external python modules
# 4. magic to enable retina (high resolution) plots
# https://gist.github.com/minrk/3301035
%matplotlib inline
%load_ext watermark
%load_ext autoreload
%autoreload 2
%config InlineBackend.figure_format = 'retina'
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_boston
from sklearn.linear_model import Ridge, RidgeCV
from sklearn.linear_model import Lasso, LassoCV
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
%watermark -a 'Jae H. Choi' -d -t -v -p numpy,pandas,matplotlib,sklearn
The watermark extension is already loaded. To reload it, use:
%reload_ext watermark
The autoreload extension is already loaded. To reload it, use:
%reload_ext autoreload
Jae H. Choi 2020-07-30 22:04:44
CPython 3.8.3
IPython 7.16.1
numpy 1.18.5
pandas 1.0.5
matplotlib 3.2.2
sklearn 0.23.1
Ridge and Lasso Regression
Recall that for a normal linear regression model of:
\[Y = \beta_0 + \beta_1X_1 + ... + \beta_pX_p\]We would estimate its coefficients using the least squares criterion, which minimizes the residual sum of squares (RSS). Or graphically, we’re fitting the blue line to our data (the black points) that minimizes the sum of the distances between the points and the blue line (sum of the red lines) as shown below.
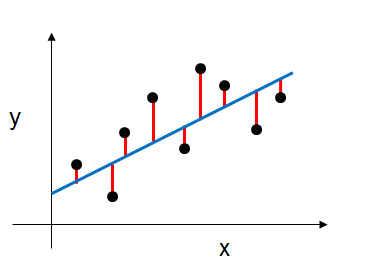
| Fig2. Bias-variance tradeoff|
Mathematically, this can be denoted as:
\[RSS = \sum_{i=1}^n \left( y_i - ( \beta_0 + \sum_{j=1}^p \beta_jx_{ij} ) \right)^2\]Where:
- \(n\) is the total number of observations (data).
- \(y_i\) is the actual output value of the observation (data).
- \(p\) is the total number of features.
- \(\beta_j\) is a model’s coefficient.
- \(x_{ij}\) is the \(i_{th}\) observation, \(j_{th}\) feature’s value.
- \(\beta_0 + \sum_{j=1}^p \beta_jx_{ij}\) is the predicted output of each observation.
Regularized linear regression models are very similar to least squares, except that the coefficients are estimated by minimizing a slightly different objective function. we minimize the sum of RSS and a “penalty term” that penalizes coefficient size.
Ridge regression (or “L2 regularization”) minimizes:
\[\text{RSS} + \alpha \sum_{j=1}^p \beta_j^2\]Lasso regression (or “L1 regularization”) minimizes:
\[\text{RSS} + \alpha \sum_{j=1}^p \lvert \beta_j \rvert\]Where \(\alpha\) is a tuning parameter that seeks to balance between the fit of the model to the data and the magnitude of the model’s coefficients:
- A tiny \(\alpha\) imposes no penalty on the coefficient size, and is equivalent to a normal linear regression.
- Increasing \(\alpha\) penalizes the coefficients and thus shrinks them towards zero.
Thus you can think of it as, we’re balancing two things to measure the model’s total quality. The RSS, measures how well the model is going to fit the data, and then the magnitude of the coefficients, which can be problematic if they become too big.
Let’s look at some examples. In the following section, we’ll load the Boston Housing Dataset, which contains some dataset about the housing values in suburbs of Boston. We’ll choose the first few features, train a ridge and lasso regression separately at look at the estimated coefficients’ weight for different \(\alpha\) parameter.
Note that we’re choosing the first few features because we’ll later use a plot to show the affect of the \(\alpha\) parameter on the estimated coefficients’ weight and too many features will make the plot pretty unappealing. The model’s interpreability or performance is not the main focus here.
# extract input and response variables (housing prices),
# meaning of each variable is in the link above
feature_num = 7
boston = load_boston()
X = boston.data[:, :feature_num]
y = boston.target
features = boston.feature_names[:feature_num]
pd.DataFrame(X, columns = features).head()
| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | |
|---|---|---|---|---|---|---|---|
| 0 | 0.00632 | 18.0 | 2.31 | 0.0 | 0.538 | 6.575 | 65.2 |
| 1 | 0.02731 | 0.0 | 7.07 | 0.0 | 0.469 | 6.421 | 78.9 |
| 2 | 0.02729 | 0.0 | 7.07 | 0.0 | 0.469 | 7.185 | 61.1 |
| 3 | 0.03237 | 0.0 | 2.18 | 0.0 | 0.458 | 6.998 | 45.8 |
| 4 | 0.06905 | 0.0 | 2.18 | 0.0 | 0.458 | 7.147 | 54.2 |
# split into training and testing sets and standardize them
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 1)
std = StandardScaler()
X_train_std = std.fit_transform(X_train)
X_test_std = std.transform(X_test)
# loop through different penalty score (alpha) and obtain the estimated coefficient (weights)
alphas = 10 ** np.arange(1, 5)
print('different alpha values:', alphas)
# stores the weights of each feature
ridge_weight = []
for alpha in alphas:
ridge = Ridge(alpha = alpha, fit_intercept = True)
ridge.fit(X_train_std, y_train)
ridge_weight.append(ridge.coef_)
different alpha values: [ 10 100 1000 10000]
def weight_versus_alpha_plot(weight, alphas, features):
"""
Pass in the estimated weight, the alpha value and the names
for the features and plot the model's estimated coefficient weight
for different alpha values
"""
fig = plt.figure(figsize = (8, 6))
# ensure that the weight is an array
weight = np.array(weight)
for col in range(weight.shape[1]):
plt.plot(alphas, weight[:, col], label = features[col])
plt.axhline(0, color = 'black', linestyle = '--', linewidth = 3)
# manually specify the coordinate of the legend
plt.legend(bbox_to_anchor = (1.3, 0.9))
plt.title('Coefficient Weight as Alpha Grows')
plt.ylabel('Coefficient weight')
plt.xlabel('alpha')
return fig
# change default figure and font size
plt.rcParams['figure.figsize'] = 8, 6
plt.rcParams['font.size'] = 12
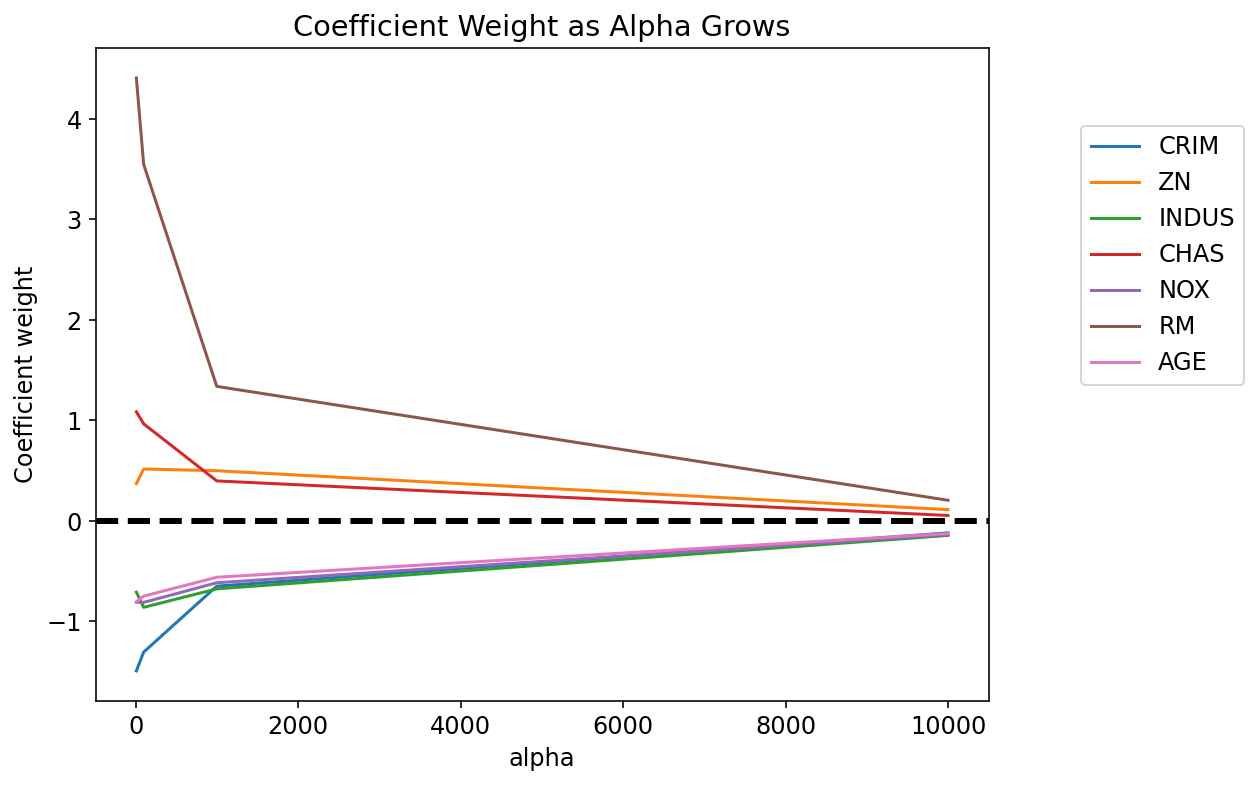
ridge_fig = weight_versus_alpha_plot(ridge_weight, alphas, features)
# does the same thing above except for lasso
alphas = [0.01, 0.1, 1, 5, 8]
print('different alpha values:', alphas)
lasso_weight = []
for alpha in alphas:
lasso = Lasso(alpha = alpha, fit_intercept = True)
lasso.fit(X_train_std, y_train)
lasso_weight.append(lasso.coef_)
lasso_fig = weight_versus_alpha_plot(lasso_weight, alphas, features)
different alpha values: [0.01, 0.1, 1, 5, 8]
Visualizing Regularization
From the result above, we can see that as the penalty value, \(\alpha\) increases:
- Lasso regression shrinks coefficients all the way to zero, thus removing them from the model.
- Ridge regression shrinks coefficients toward zero, but they rarely reach zero.
To get a sense of why this is happening, the visualization below depicts what happens when we apply the two different regularization. The general idea is that we are restricting the allowed values of our coefficients to a certain “region” and within that region, we wish to find the coefficients that result in the best model.
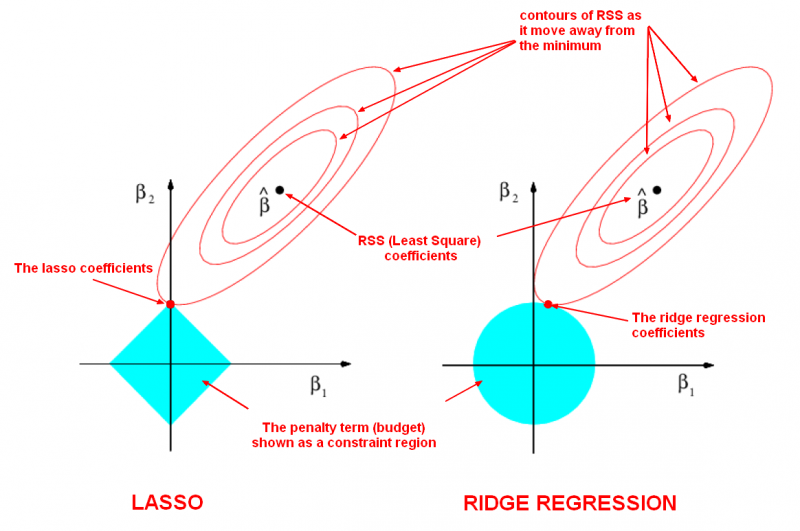
| Fig3. Lasso and Ridge Coefficient Plots|
In this diagram, we are fitting a linear regression model with two features, \(x_1\) and \(x_2\).
- \(\hat\beta\) represents the set of two coefficients, \(\beta_1\) and \(\beta_2\), which minimize the RSS for the unregularized model.
- The ellipses that are centered around \(\hat\beta\) represent regions of constant RSS. In other words, all of the points on a given ellipse share a common value of the RSS, despite the fact that they may have different values for \(\beta_1\) and \(\beta_2\). As the ellipses expand away from the least squares coefficient estimates, the RSS increases.
- Regularization restricts the allowed positions of \(\hat\beta\) to the blue constraint region. In this case, \(\hat\beta\) is not within the blue constraint region. Thus, we need to move \(\hat\beta\) until it intersects the blue region, while increasing the RSS as little as possible.
- For ridge, this region is a circle because it constrains the square of the coefficients. Thus the intersection will not generally occur on an axis, and so the coefficient estimates will be typically be non-zero.
- For lasso, this region is a diamond because it constrains the absolute value of the coefficients. Because the constraint has corners at each of the axes, and so the ellipse will often intersect the constraint region at an axis. When this occurs, one of the coefficients will equal zero. In higher dimensions, many of the coefficient estimates may equal zero simultaneously. In the figure above, the intersection occurs at \(\beta_1 = 0\), and so the resulting model will only include \(\beta_2\).
- The size of the blue constraint region is determined by \(\alpha\), with a smaller \(\alpha\) resulting in a larger region:
- When \(\alpha\) is zero, the blue region is infinitely large, and thus the coefficient sizes are not constrained.
- When \(\alpha\) increases, the blue region gets smaller and smaller.
Advice For Applying Regularization
Signs and causes of overfitting in the original regression model
- Linear models can overfit if you include irrelevant features, meaning features that are unrelated to the response. Or if you include highly correlated features, meaning two or more predictor variables are closely related to one another. Because it will learn a coefficient for every feature you include in the model, regardless of whether that feature has the signal or the noise. This is especially a problem when \(p\) (number of features) is close to \(n\) (number of observations).
- Linear models that have large estimated coefficients is a sign that the model may be overfitting the data. The larger the absolute value of the coefficient, the more power it has to change the predicted response, resulting in a higher variance.
Should features be standardized?
Yes, because L1 and L2 regularizers of linear models assume that all features are centered around 0 and have variance in the same order. If a feature has a variance that is orders of magnitude larger that others, features would be penalized simply because of their scale and make the model unable to learn from other features correctly as expected. Also, standardizing avoids penalizing the intercept, which wouldn’t make intuitive sense.
How should we choose between Lasso regression (L1) and Ridge regression (L2)?
- If model performance is our primary concern or that we are not concerned with explicit feature selection, it is best to try both and see which one works better. Usually L2 regularization can be expected to give superior performance over L1.
- Note that there’s also a ElasticNet regression, which is a combination of Lasso regression and Ridge regression.
- Lasso regression is preferred if we want a sparse model, meaning that we believe many features are irrelevant to the output.
- When the dataset includes collinear features, Lasso regression is unstable in a similar way as unregularized linear models are, meaning that the coefficients (and thus feature ranks) can vary significantly even on small data changes. We will elaborate on this point in the following section.
When using L2-norm, since the coefficients are squared in the penalty expression, it has a different effect from L1-norm, namely it forces the coefficient values to be spread out more equally. When the dataset at hand contains correlated features, it means that these features should get similar coefficients. Using an example of a linear model \(Y = X1 + X2\), with strongly correlated feature of \(X1\) and \(X2\), then for L1-norm, the penalty is the same whether the learned model is \(Y=1∗X1+1∗X2\) or \(Y=2∗X1+0∗X2\). In both cases the penalty is \(2∗α\). For L2-norm, however, the first model’s penalty is \(1^2+1^2=2α\), while for the second model is penalized with \(2^2+0^2=4α\).
The effect of this is that models are much more stable (coefficients do not fluctuate on small data changes as is the case with unregularized or L1 models). So while L2 regularization does not perform feature selection the same way as L1 does, it is more useful for feature interpretation due to its stability and the fact that useful features still tend to have non-zero coefficients. But again, please do remove collinear features to prevent a bunch of downstream headaches.
def generate_random_data(size, seed):
"""Example of collinear features existing within the data"""
rstate = np.random.RandomState(seed)
X_seed = rstate.normal(0, 1, size)
X1 = X_seed + rstate.normal(0, .1, size)
X2 = X_seed + rstate.normal(0, .1, size)
X3 = X_seed + rstate.normal(0, .1, size)
y = X1 + X2 + X3 + rstate.normal(0, 1, size)
X = np.array([X1, X2, X3]).T
return X, y
def pretty_print_linear(estimator, names = None, sort = False):
"""A helper method for pretty-printing linear models' coefficients"""
coef = estimator.coef_
if names is None:
names = ['X%s' % x for x in range(1, len(coef) + 1)]
info = zip(coef, names)
if sort:
info = sorted(info, key = lambda x: -np.abs(x[0]))
output = ['{} * {}'.format(round(coef, 3), name) for coef, name in info]
output = ' + '.join(output)
return output
# We run the two method 10 times with different random seeds
# confirming that Ridge is more stable than Lasso
size = 100
for seed in range(10):
print('Random seed:', seed)
X, y = generate_random_data(size, seed)
lasso = Lasso()
lasso.fit(X, y)
print('Lasso model:', pretty_print_linear(lasso))
ridge = Ridge(alpha = 10)
ridge.fit(X, y)
print('Ridge model:', pretty_print_linear(ridge))
print()
Random seed: 0
Lasso model: 0.486 * X1 + 1.508 * X2 + 0.0 * X3
Ridge model: 0.938 * X1 + 1.059 * X2 + 0.877 * X3
Random seed: 1
Lasso model: 1.034 * X1 + 0.626 * X2 + 0.0 * X3
Ridge model: 0.984 * X1 + 1.068 * X2 + 0.759 * X3
Random seed: 2
Lasso model: 1.361 * X1 + 0.0 * X2 + 0.782 * X3
Ridge model: 0.972 * X1 + 0.943 * X2 + 1.085 * X3
Random seed: 3
Lasso model: 0.0 * X1 + 1.008 * X2 + 1.134 * X3
Ridge model: 0.919 * X1 + 1.005 * X2 + 1.033 * X3
Random seed: 4
Lasso model: 0.27 * X1 + 0.0 * X2 + 1.832 * X3
Ridge model: 0.964 * X1 + 0.982 * X2 + 1.098 * X3
Random seed: 5
Lasso model: 0.0 * X1 + 0.035 * X2 + 1.854 * X3
Ridge model: 0.758 * X1 + 1.011 * X2 + 1.139 * X3
Random seed: 6
Lasso model: 0.486 * X1 + 0.0 * X2 + 1.601 * X3
Ridge model: 1.016 * X1 + 0.89 * X2 + 1.091 * X3
Random seed: 7
Lasso model: 0.441 * X1 + 0.036 * X2 + 1.582 * X3
Ridge model: 1.018 * X1 + 1.039 * X2 + 0.901 * X3
Random seed: 8
Lasso model: 0.28 * X1 + 1.974 * X2 + 0.0 * X3
Ridge model: 0.907 * X1 + 1.071 * X2 + 1.008 * X3
Random seed: 9
Lasso model: 0.0 * X1 + 0.0 * X2 + 1.912 * X3
Ridge model: 0.896 * X1 + 0.903 * X2 + 0.98 * X3
How do we choose the \(\alpha\) parameter?
We can either use a validation set if we have lots of data or use cross validation for smaller data sets. See a quick examples below that uses cross validation with RidgeCV and LassoCV, which is function that performs ridge regression and lasso regression with built-in cross-validation of the alpha parameter.
From R’s glmnet package vignette
It is known that the ridge penalty shrinks the coefficients of correlated predictors towards each other while the lasso tends to pick one of them and discard the others. The elastic-net penalty mixes these two; if predictors are correlated in groups, an \(\alpha = 0.5\) tends to select the groups in or out together. This is a higher level parameter, and users might pick a value upfront, else experiment with a few different values. One use of \(\alpha\) is for numerical stability; for example, the elastic net with \(\alpha = 1−\epsilon\) for some small \(\epsilon > 0\) performs much like the lasso, but removes any degeneracies and wild behavior caused by extreme correlations.
# alpha: array of alpha values to try; must be positive, increase for more regularization
# create an array of alpha values and select the best one with RidgeCV
alpha_range = 10. ** np.arange(-2, 3)
ridge_cv = RidgeCV(alphas = alpha_range, fit_intercept = True)
ridge_cv.fit(X_train_std, y_train)
# examine the coefficients and the errors of the predictions
# using the best alpha value
y_pred = ridge_cv.predict(X_test_std)
print('coefficients:\n', ridge_cv.coef_)
print('best alpha:\n' , ridge_cv.alpha_)
print('\nRSS:', np.sum((y_test - y_pred) ** 2))
coefficients:
[-1.49246448 0.37088936 -0.70836731 1.08568161 -0.80970633 4.4075122
-0.80450999]
best alpha:
10.0
RSS: 4366.321935003472
# n_alphas: number of alpha values (automatically chosen) to try
# select the best alpha with LassoCV
lasso_cv = LassoCV(n_alphas = 10, fit_intercept = True)
lasso_cv.fit(X_train_std, y_train)
# examine the coefficients and the errors of the predictions
# using the best alpha value
y_pred = lasso_cv.predict(X_test_std)
print('coefficients:\n', lasso_cv.coef_)
print('best alpha:\n', lasso_cv.alpha_)
print('\nRSS:', np.sum(( y_test - y_pred ) ** 2))
coefficients:
[-1.5149245 0.34021279 -0.67185865 1.09280671 -0.81071974 4.53310098
-0.81752854]
best alpha:
0.005835182912170716
RSS: 4296.025010307988
To sum it up, overfitting is when we build a predictive model that fits the data “too closely”, so that it captures the random noise in the data rather than true patterns. As a result, the model predictions will be wrong when applied to new data. Give that our data is sufficiently large and clean, regularization is one good way to prevent overfitting from occurring.
Leave a comment